Netflix Kafka’yı kullanıyor mu?
Netflix Studio ve Finance World’de Apache Kafka’nın yer aldığı
Özet:
Netflix’te, çoğu uygulama Keystone Boru Hattı’na veri üretmek için Java İstemci Kitaplığı’nı kullanır. Boru hattı, verileri toplamak ve tamponlamaktan sorumlu Kafka kümelerinden ve gerçek zamanlı tüketiciler için konular içeren tüketici Kafka kümelerinden oluşmaktadır. Netflix, günde 700 milyardan fazla mesajı işleyen toplam 36 Kafka kümesi işletiyor. Kayıpsız teslimat elde etmek için, boru hattı 0’dan daha düşük bir veri kaybı oranına izin verir.% 01. Üreticiler ve brokerler, kullanılabilirliği ve iyi kullanıcı deneyimini sağlayacak şekilde yapılandırılmıştır.
Anahtar noktaları:
- Netflix uygulamaları, Keystone Boru Hattı’na veri üretmek için Java İstemci Kitaplığı’nı kullanın
- Her uygulama örneğinde birden fazla Kafka üreticisi var
- Kafka kümeleri ön plana çıkarma ve arabelleğe alın
- Tüketici Kafka kümeleri gerçek zamanlı tüketiciler için konular içerir
- Netflix, günde 700 milyardan fazla mesajla 36 Kafka kümesi işletiyor
- Veri kaybı oranı 0’dan az.% 01
- Üreticiler ve brokerler kullanılabilirliği sağlamak için yapılandırılmıştır
- Üreticiler konu yönlendirme ve lavabo izolasyonu için dinamik yapılandırma kullanır
- Java olmayan uygulamalar, Keystone Rest uç noktalarına etkinlik gönderebilir
- Mesaj siparişi toplu işleme veya yönlendirme katmanında oluşturulur
Sorular:
- Netflix uygulamaları Keystone boru hattına nasıl veri üretir??
- Kafka kümelerinin ön rolleri nelerdir?
- Keystone Boru Hattı’nda ne tür Kafka kümesi var?
- Netflix kaç tane Kafka kümesi çalışıyor?
- Netflix için ortalama veri alma oranı nedir?
- Netflix tarafından kullanılan Kafka’nın şu anki sürümü nedir?
- Netflix boru hattında kayıpsız teslimat nasıl elde eder??
- Kullanılabilirliği sağlamak için üreticilerin ve brokerlerin yapılandırma nedir??
- Mesaj siparişi nasıl korunur?
- Müşteri uygulamaları neden doğrudan Kafka Kümeleri ön plandan tüketmiyor??
- Kafka’yı bulutta çalıştırırken ne zorluklar ortaya çıkıyor?
- Çoğaltma Kafka’nın kullanılabilirliğini nasıl etkiler??
- Netflix olayları ele almak ve küme stabilitesini korumak için ne yaptı??
- Netflix’in Kafka kümeleri için dağıtım stratejisi nedir?
Çoğu Netflix uygulaması, Keystone Boru Hattı’na veri üretmek için Java İstemci Kitaplığı’nı kullanır. Her uygulama örneğinin birden çok Kafka üreticisi vardır.
Kafka kümeleri ön üreticilerden mesaj toplayın ve arabelleğe alın. Mesaj enjeksiyonu için bir geçit görevi görürler.
Anahtar taşı boru hattı, Kafka kümeleri ve tüketici Kafka kümelerinden oluşur.
Netflix 36 Kafka kümesi işletiyor.
Netflix günde 700 milyardan fazla mesaj alıyor.
Netflix Kafka sürümünden geçiyor 0.8.2.1 ila 0.9.0.1.
Büyük veri hacmini hesaba katan Netflix, kabul edilebilir miktarda veri kaybını kabul etmek için ekiplerle birlikte çalıştı ve günlük veri kaybı oranı 0’dan az.% 01.
Yapımcılar ve brokerler “Acks = 1”, blok ile yapılandırılmıştır.Açık.tampon.Full = false “ve” kirli.Önder.seçim.enable = true “.
Üreticiler anahtarlı mesajları kullanmaz ve toplu işleme katmanında veya yönlendirme katmanında mesaj siparişi yeniden kurulur.
Öngörülebilir yük ve stabilite sağlamak için müşteri uygulamalarının ön plana çıkma Kafka kümelerinden doğrudan tüketmesine izin verilmez.
Kafka’yı bulutta çalıştırmak, öngörülemeyen örnek yaşam döngüsü, geçici ağ sorunları ve performans sorunlarına neden olan aykırı değerler gibi zorluklar yaratıyor.
Çoğaltma kullanılabilirliği artırır, ancak aykırı bir broker, çoğaltma gecikmesi ve tampon tükenmesi nedeniyle basamaklı efektlere ve mesaj düşüşüne neden olabilir.
Netflix, durum ve karmaşıklığı azalttı, aykırı tespit uyguladı ve olaylardan hızlı bir şekilde kurtulmak için önlemler geliştirdi.
Netflix, bağımlılıkları azaltmak ve istikrarı artırmak için bir dev küme üzerinde birden fazla küçük Kafka kümesini destekler.
Kafka Keystone Boru Hattı
Keystone Boru Hattı’nda iki Kafka Kümesi var: Kafka ve Tüketici Kafka Fronting. Kafka kümeleri, Netflix’teki neredeyse her uygulama örneği olan üreticilerden mesaj almaktan sorumludur. Rolleri, aşağı akış sistemleri için veri toplama ve tamponlama. Tüketici Kafka Kümeleri, gerçek zamanlı tüketiciler için Samza tarafından yönlendirilen bir konu alt kümesini içerir.
Şu anda hem ön planda Kafka hem de Tüketici Kafka için 4.000’den fazla broker örneğinden oluşan 36 Kafka kümesi işletiyoruz. Ortalama bir günde 700 milyardan fazla mesaj alındı. Şu anda Kafka sürüm 0’dan geçiş yapıyoruz.8.2.1 ila 0.9.0.1.
Tasarım ilkeleri
Mevcut Kafka mimarisi ve büyük veri hacmimiz göz önüne alındığında, veri boru hattımız için kayıpsız teslimat elde etmek AWS EC2’de maliyet engelleyicidir. Bunun muhasebesi, biz’VE, maliyeti dengelerken, kabul edilebilir miktarda veri kaybına ulaşmak için altyapımıza bağlı ekiplerle çalıştı. Biz’VE, 0’dan az günlük veri kaybı oranı elde etti.% 01. Metrikler düşmüş mesajlar için toplanır, böylece gerekirse harekete geçebiliriz.
Keystone boru hattı, uygulamaları engellemeden eşzamansız olarak mesajlar üretir. Bir mesaj, yeniden denemeden sonra teslim edilemezse, uygulamanın kullanılabilirliğini ve iyi kullanıcı deneyimini sağlamak için üretici tarafından bırakılacaktır. Bu yüzden yapımcımız ve brokerimiz için aşağıdaki yapılandırmayı seçtik:
- Acks = 1
- engellemek.Açık.tampon.Full = Yanlış
- kirli.Önder.seçim.Enable = true
Netflix’teki uygulamaların çoğu, Keystone Boru Hattı’na üretmek için Java İstemci Kütüphanemizi kullanıyor. Bu uygulamaların her örneğinde, her biri lavabo seviyesi izolasyonu için ön planda bir Kafka kümesine üreten birden fazla Kafka üreticisi vardır. Üreticiler, başvuru işlemini yeniden başlatmak zorunda kalmadan çalışma zamanında değiştirilebilen dinamik yapılandırma yoluyla yönlendirilen esnek konu yönlendirme ve lavabo yapılandırmasına sahiptir. Bu, trafiği yeniden yönlendirmek ve Kafka kümelerine göç etmek gibi şeyler için mümkün kılar. Java olmayan uygulamalar için, mesajları ön plana çıkaran Keystone Rest uç noktalarına olay göndermeyi seçebilirler.
Daha fazla esneklik için üreticiler anahtarlı mesajlar kullanmazlar. Toplu işleme katmanında (Hive / Elasticsearch) veya tüketicileri akış için yönlendirme katmanında yaklaşık mesaj siparişi yeniden kurulur.
Fronting Kafka kümelerimizin istikrarını yüksek öncelikli bir şekilde koyduk, çünkü bunlar mesaj enjeksiyonu için geçit. Bu nedenle, öngörülebilir yüke sahip olduklarından emin olmak için istemci uygulamalarının doğrudan onlardan tüketmesine izin vermiyoruz.
Kafka’yı bulutta çalıştırmanın zorlukları
Kafka, LinkedIn’de dağıtım hedefi olarak veri merkezi ile geliştirildi. Kafka’nın bulutta daha iyi çalışmasını sağlamak için dikkate değer çaba sarf ettik.
Bulutta, örnekler öngörülemeyen bir yaşam döngüsüne sahiptir ve donanım sorunları nedeniyle herhangi bir zamanda feshedilebilir. Geçici ağ sorunları bekleniyor. Bunlar vatansız hizmetler için sorun değil, Zookeeper ve koordinasyon için tek bir kontrolör gerektiren durumlu bir hizmet için büyük bir zorluk oluşturmaktadır.
Sorunlarımızın çoğu aykırı brokerlerle başlıyor. Bir aykırı değer, eşit olmayan iş yükü, donanım sorunları veya özel ortamı, örneğin, çok kiracılıktan dolayı gürültülü komşulardan kaynaklanabilir. Bir aykırı broker, isteklere veya sık TCP zaman aşımlarına/yeniden iletimlere yavaş yanıtlar olabilir. Böyle bir komisyoncuya etkinlik gönderen yapımcılar, yanıtları beklerken yerel arabelleklerini tüketme şansına sahip olacaklar, ardından mesaj düşüşü kesin bir. Tampon tükenmesine katkıda bulunan bir diğer faktör, Kafka 0.8.2 Yapımcı Yapmıyor’t Tamponda bekleyen mesajlar için zaman aşımını destekleyin.
Kafka’S çoğaltma kullanılabilirliği artırır. Bununla birlikte, replikasyon, bir aykırı değerlerin basamaklı etkiye neden olabileceği brokerler arasında bağımlılıklara yol açar. Bir aykırı olarak çoğaltmayı yavaşlatırsa, çoğaltma gecikmesi birikebilir ve sonunda bölüm liderlerinin çoğaltma isteklerini sunmak için diskten okumasına neden olabilir. Bu, etkilenen brokerleri yavaşlatır ve sonunda üreticilerin önceki durumda açıklandığı gibi bitkin tampon nedeniyle mesaj düşürmesine neden olur.
Kafka’yı işletmenin ilk günlerinde, üreticilerin bir Zookeeper sorunu nedeniyle yüzlerce örneğe sahip bir Kafka kümesine önemli miktarda mesaj bıraktıkları bir olay yaşadık. Yüzlerce broker ile küçük bir zaman penceresinde böyle hata ayıklama sorunları gerçekçi değil.
Olaydan sonra, Kafka kümelerimiz için durum ve karmaşıklığı azaltmak, aykırı değerleri tespit etmek ve bir olay meydana geldiğinde temiz bir durumla hızlı bir şekilde başlamak için bir yol bulmak için çaba sarf edildi.
Kafka Dağıtım Stratejisi
Kafka kümelerini dağıtmak için kullandığımız temel stratejiler aşağıdadır:
- Bir dev kümenin aksine birden fazla küçük Kafka kümesini tercih et. Bu bağımlılıkları azaltır ve istikrarı iyileştirir.
- Sorunlu brokerleri tanımlamak ve işlemek için aykırı algılama mekanizmalarını uygulayın.
- Olaylardan hızlı bir şekilde kurtulmak ve temiz bir durumla başlamak için önlemler geliştirin.
Netflix Studio ve Finance World’de Apache Kafka’nın yer aldığı
Netflix’teki uygulamaların çoğu, Keystone Boru Hattı’na üretmek için Java İstemci Kütüphanemizi kullanıyor. Bu uygulamaların her örneğinde, her biri lavabo seviyesi izolasyonu için ön planda bir Kafka kümesine üreten birden fazla Kafka üreticisi vardır. Üreticiler, başvuru işlemini yeniden başlatmak zorunda kalmadan çalışma zamanında değiştirilebilen dinamik yapılandırma yoluyla yönlendirilen esnek konu yönlendirme ve lavabo yapılandırmasına sahiptir. Bu, trafiği yeniden yönlendirmek ve Kafka kümelerine göç etmek gibi şeyler için mümkün kılar. Java olmayan uygulamalar için, mesajları ön plana çıkaran Keystone Rest uç noktalarına olay göndermeyi seçebilirler.
Kafka Keystone Boru Hattı
Keystone Boru Hattı’nda iki Kafka Kümesi var: Kafka ve Tüketici Kafka Fronting. Kafka kümeleri, Netflix’teki neredeyse her uygulama örneği olan üreticilerden mesaj almaktan sorumludur. Rolleri, aşağı akış sistemleri için veri toplama ve tamponlama. Tüketici Kafka Kümeleri, gerçek zamanlı tüketiciler için Samza tarafından yönlendirilen bir konu alt kümesini içerir.
Şu anda hem ön planda Kafka hem de Tüketici Kafka için 4.000’den fazla broker örneğinden oluşan 36 Kafka kümesi işletiyoruz. Ortalama bir günde 700 milyardan fazla mesaj alındı. Şu anda Kafka sürüm 0’dan geçiş yapıyoruz.8.2.1 ila 0.9.0.1.
Tasarım ilkeleri
Mevcut Kafka mimarisi ve büyük veri hacmimiz göz önüne alındığında, veri boru hattımız için kayıpsız teslimat elde etmek AWS EC2’de maliyet engelleyicidir. Bunun muhasebesi, biz’VE, maliyeti dengelerken, kabul edilebilir miktarda veri kaybına ulaşmak için altyapımıza bağlı ekiplerle çalıştı. Biz’VE, 0’dan az günlük veri kaybı oranı elde etti.% 01. Metrikler düşmüş mesajlar için toplanır, böylece gerekirse harekete geçebiliriz.
Keystone boru hattı, uygulamaları engellemeden eşzamansız olarak mesajlar üretir. Bir mesaj, yeniden denemeden sonra teslim edilemezse, uygulamanın kullanılabilirliğini ve iyi kullanıcı deneyimini sağlamak için üretici tarafından bırakılacaktır. Bu yüzden yapımcımız ve brokerimiz için aşağıdaki yapılandırmayı seçtik:
- Acks = 1
- engellemek.Açık.tampon.Full = Yanlış
- kirli.Önder.seçim.Enable = true
Netflix’teki uygulamaların çoğu, Keystone Boru Hattı’na üretmek için Java İstemci Kütüphanemizi kullanıyor. Bu uygulamaların her örneğinde, her biri lavabo seviyesi izolasyonu için ön planda bir Kafka kümesine üreten birden fazla Kafka üreticisi vardır. Üreticiler, başvuru işlemini yeniden başlatmak zorunda kalmadan çalışma zamanında değiştirilebilen dinamik yapılandırma yoluyla yönlendirilen esnek konu yönlendirme ve lavabo yapılandırmasına sahiptir. Bu, trafiği yeniden yönlendirmek ve Kafka kümelerine göç etmek gibi şeyler için mümkün kılar. Java olmayan uygulamalar için, mesajları ön plana çıkaran Keystone Rest uç noktalarına olay göndermeyi seçebilirler.
Daha fazla esneklik için üreticiler anahtarlı mesajlar kullanmazlar. Toplu işleme katmanında (Hive / Elasticsearch) veya tüketicileri akış için yönlendirme katmanında yaklaşık mesaj siparişi yeniden kurulur.
Fronting Kafka kümelerimizin istikrarını yüksek öncelikli bir şekilde koyduk, çünkü bunlar mesaj enjeksiyonu için geçit. Bu nedenle, öngörülebilir yüke sahip olduklarından emin olmak için istemci uygulamalarının doğrudan onlardan tüketmesine izin vermiyoruz.
Kafka’yı bulutta çalıştırmanın zorlukları
Kafka, LinkedIn’de dağıtım hedefi olarak veri merkezi ile geliştirildi. Kafka’nın bulutta daha iyi çalışmasını sağlamak için dikkate değer çaba sarf ettik.
Bulutta, örnekler öngörülemeyen bir yaşam döngüsüne sahiptir ve donanım sorunları nedeniyle herhangi bir zamanda feshedilebilir. Geçici ağ sorunları bekleniyor. Bunlar vatansız hizmetler için sorun değil, Zookeeper ve koordinasyon için tek bir kontrolör gerektiren durumlu bir hizmet için büyük bir zorluk oluşturmaktadır.
Sorunlarımızın çoğu aykırı brokerlerle başlıyor. Bir aykırı değer, eşit olmayan iş yükü, donanım sorunları veya özel ortamı, örneğin, çok kiracılıktan dolayı gürültülü komşulardan kaynaklanabilir. Bir aykırı broker, isteklere veya sık TCP zaman aşımlarına/yeniden iletimlere yavaş yanıtlar olabilir. Böyle bir komisyoncuya etkinlik gönderen yapımcılar, yanıtları beklerken yerel arabelleklerini tüketme şansına sahip olacaklar, ardından mesaj düşüşü kesin bir. Tampon tükenmesine katkıda bulunan bir diğer faktör, Kafka 0.8.2 Yapımcı Yapmıyor’t Tamponda bekleyen mesajlar için zaman aşımını destekleyin.
Kafka’S çoğaltma kullanılabilirliği artırır. Bununla birlikte, replikasyon, bir aykırı değerlerin basamaklı etkiye neden olabileceği brokerler arasında bağımlılıklara yol açar. Bir aykırı olarak çoğaltmayı yavaşlatırsa, çoğaltma gecikmesi birikebilir ve sonunda bölüm liderlerinin çoğaltma isteklerini sunmak için diskten okumasına neden olabilir. Bu, etkilenen brokerleri yavaşlatır ve sonunda üreticilerin önceki durumda açıklandığı gibi bitkin tampon nedeniyle mesaj düşürmesine neden olur.
Kafka’yı işletmenin ilk günlerinde, üreticilerin bir Zookeeper sorunu nedeniyle yüzlerce örneğe sahip bir Kafka kümesine önemli miktarda mesaj bıraktıkları bir olay yaşadık. Yüzlerce broker ile küçük bir zaman penceresinde böyle hata ayıklama sorunları gerçekçi değil.
Olaydan sonra, Kafka kümelerimiz için durum ve karmaşıklığı azaltmak, aykırı değerleri tespit etmek ve bir olay meydana geldiğinde temiz bir durumla hızlı bir şekilde başlamak için bir yol bulmak için çaba sarf edildi.
Kafka Dağıtım Stratejisi
Kafka kümelerini dağıtmak için kullandığımız temel stratejiler aşağıdadır
- Bir dev kümenin aksine birden fazla küçük Kafka kümesini tercih et. Bu, her küme için operasyonel karmaşıklığı azaltır. En büyük kümemizde 200’den az broker var.
- Her kümedeki bölüm sayısını sınırlayın. Her kümenin 10.000’den az bölümü vardır. Bu, kullanılabilirliği artırır ve bölüm sayısına bağlı talep/yanıt için gecikmeyi azaltır.
- Her konu için kopyaların eşit olarak dağıtılması için çabalayın. Aykırı değerlerin kapasite planlaması ve tespiti için iş yükü bile daha kolaydır.
- Zookeeper sorunlarının etkisini azaltmak için her Kafka kümesi için özel hayvanat bahçesi kümesi kullanın.
Aşağıdaki tabloda dağıtım yapılandırmalarımızı göstermektedir.
Kafka yük devretme
Birincil küme başı dertte olduğunda hem üretici hem de tüketici (yönlendirici) trafiğini yeni bir Kafka kümesine yükleyebileceğimiz bir süreci otomatikleştirdik. Her ön planda Kafka kümesi için, istenen başlatma yapılandırmasına sahip soğuk bir bekleme kümesi vardır, ancak minimum başlangıç kapasitesi. Başlamak için temiz bir durumu garanti etmek için, yük devretme kümesinde oluşturulan konu yoktur ve Zookeeper kümesini birincil Kafka kümesiyle paylaşmaz. Yük devretme kümesi, orijinal kümenin sahip olabileceği herhangi bir çoğaltma sorunundan arınmış olacak şekilde çoğaltma faktörü 1’e sahip olacak şekilde tasarlanmıştır.
Yük devretme olduğunda, üreticiyi ve tüketici trafiğini yönlendirmek için aşağıdaki adımlar atılır:
- Yük devretme kümesini istenen boyuta yeniden boyutlandırın.
- Yük Devretme Kümesi için Konular Oluşturun ve Yönlendirme İşlerini Paralel olarak başlatın.
- (İsteğe bağlı olarak) Partların liderlerinin, üretirken ilk mesaj düşüşünü en aza indirmek için denetleyici tarafından kurulmasını bekleyin.
- Üretici trafiğini yük devretme kümesine değiştirmek için üretici yapılandırmasını dinamik olarak değiştirin.
Yük devretme senaryosu aşağıdaki grafikle tasvir edilebilir:
Sürecin tam otomasyonu ile 5 dakikadan daha kısa bir sürede yük devretebiliriz. Yük devretme başarılı bir şekilde tamamlandıktan sonra, günlükleri ve metrikleri kullanarak sorunları orijinal küme ile hata ayıklayabiliriz. Trafiği geri almadan önce kümeyi tamamen yok etmek ve yeni görüntülerle yeniden inşa etmek de mümkündür. Aslında, çevrimdışı bakım yaparken trafiği yönlendirmek için genellikle yük devretme stratejisi kullanırız. Kafka kümelerimizi Rolling yükseltmesini yapmak veya Broker Arası İletişim Protokolü sürümünü ayarlamak zorunda kalmadan yeni Kafka sürümüne bu şekilde yükseltiyoruz.
Kafka için gelişme
Kafka için çok sayıda yararlı araç geliştirdik. İşte bazı önemli noktalar:
Yapımcı yapışkan bölme
Bu, Java Yapımcı Kütüphanesi için geliştirdiğimiz özel bir özelleştirilmiş bölümçidir. Adından da anlaşılacağı gibi, bir sonraki bölümü rastgele seçmeden önce yapılandırılabilir bir süre için belirli bir bölüme yapışır. Yapışkan Bölümcüyü Lingering ile birlikte kullanmanın, mesaj toplu işlemini iyileştirmeye ve komisyoncunun yükünü azaltmaya yardımcı olduğunu gördük. İşte yapışkan bölüm sahibinin etkisini gösteren tablo:
Rack Fiel Field Replica Ataması
Tüm Kafka kümelerimiz üç AWS kullanılabilirlik bölgesine yayılıyor. AWS Kullanılabilirlik Bölgesi kavramsal olarak bir raftır. Bir bölgenin düşmesi durumunda kullanılabilirliği sağlamak için, aynı konu için kopyaların farklı bölgelere atanması için raf (Bölge) farkında çoğaltma atamasını geliştirdik. Bu sadece bir bölge kesintisi riskini azaltmaya yardımcı olmakla kalmaz, aynı zamanda aynı fiziksel ana bilgisayarda birlikte bulunan birden fazla broker, konakçı sorunları nedeniyle feshedildiğinde kullanılabilirliğimizi de artırır. Bu durumda, Kafka’dan daha iyi hata toleransımız var’S n – 1 burada n replikasyon faktörüdür.
Çalışma KIP-36 ve Apache Kafka Github Çekme İsteği #132’de Kafka topluluğuna katkıda bulundu.
Kafka Meta Veri Visudier
Kafka’S meta verileri hayvanat bahçesinde saklanır. Bununla birlikte, katılımcı tarafından sağlanan ağaç görünümünde gezinmesi zordur ve bilgileri bulmak ve ilişkilendirmek için zaman alıcıdır.
Meta verileri görselleştirmek için kendi kullanıcı arayüzümüzü oluşturduk. Hem grafik hem de tablo görünümleri sağlar ve ISR durumunu belirtmek için zengin renk şemaları kullanır. Temel özellikler aşağıdadır:
- Komisyoncular, konular ve kümeler için görüntüler için bireysel sekme
- Çoğu bilgi sıralanabilir ve aranabilir
- Kümelerde konuları aramak
- Broker Kimliğinden AWS Örnek Kimliğine doğrudan eşleme
- Lider-takipçi ilişkisi ile brokerlerin korelasyonu
Kullanıcı arayüzünün ekran görüntüleri şunlardır:
İzleme
Kafka için özel bir izleme hizmeti oluşturduk. İzlemeden sorumludur:
- Broker durumu (özellikle ZooKeeper’dan çevrimdışı ise)
- Komisyoncu’Üreticilerden mesaj alabilme ve tüketicilere mesaj gönderme yeteneği. İzleme hizmeti, sürekli kalp atışı mesajları için hem üretici hem de tüketici görevi görür ve bu mesajların gecikmesini ölçer.
- Eski hayvanat bahçesi merkezli tüketiciler için, her bölümün tüketildiğinden emin olmak için tüketici grubunun bölüm sayısını izler.
- Keystone Samza yönlendiricileri için, kontrol noktası ofsetlerini izler ve komisyoncu ile karşılaştırır’Sap ofsets, sıkışıp kalmadıklarından ve önemli bir gecikme olmadığından emin olmak için.
Buna ek olarak, trafik akışını bir konu seviyesine ve brokerin çoğuna kadar izlemek için kapsamlı gösterge tablolarımız var’S metrikleri.
Gelecek planı
Şu anda Kafka’ya göç etme sürecindeyiz 0.9, yeni tüketici API’leri, yapımcı mesaj zaman aşımı ve kotalar dahil olmak üzere kullanmak istediğimiz birkaç özelliğe sahip. Ayrıca Kafka kümelerimizi AWS VPC’ye taşıyacağız ve geliştirilmiş ağının (EC2 Classic ile karşılaştırıldığında) kullanılabilirliği ve kaynak kullanımını iyileştirmek için bize bir avantaj sağlayacağına inanacağız.
Konular için katmanlı bir SLA sunacağız. Küçük kaybı kabul edebilecek konular için bir kopya kullanmayı düşünüyoruz. Çoğaltma olmadan, sadece bant genişliğinde büyük tasarruf değil, aynı zamanda denetleyiciye bağlı olması gereken durum değişikliklerini de en aza indiriyoruz. Bu, vatansız hizmetleri destekleyen bir ortamda Kafka’yı daha az durumsal hale getirmek için başka bir adımdır. Dezavantajı, bir broker ortadan kalktığında potansiyel mesaj kaybıdır. Ancak, 0’da üretici mesaj zaman aşımından yararlanarak.9 Serbest bırakma ve muhtemelen AWS EBS hacmi, kaybı azaltabiliriz.
Yönlendirme Altyapımız, Konteyner Yönetimi, Akış İşleme ve daha fazlası hakkında gelecekteki Keystone blogları için bizi izlemeye devam edin!
Netflix Studio ve Finance World’de Apache Kafka’nın yer aldığı
Netflix, 2019’da birinci sınıf orijinal içerik üretmek için tahmini 15 milyar dolar harcadı. Bahisler çok yüksek olduğunda, işimizi planlamaya, harcamaları belirlemeye ve tüm Netflix içeriğini hesaba katan kritik bilgilerle etkinleştirmek çok önemlidir. Bu bilgiler şunları içerebilir:
- Önümüzdeki yıl uluslararası filmler ve dizilerde ne kadar harcamalıyız??
- Üretim bütçemizi aşmak için trend muyuz ve herkesin yolda tutmak için adım atması mı gerekiyor??
- Mümkün olan en iyi arduvazın oluşturulmasına yardımcı olmak için bir katalogu veri, sezgi ve analitikle nasıl programlarız?
- Dünyanın dört bir yanındaki içerik için nasıl finansal üretiyoruz ve Wall Street’e rapor veriyoruz?
VC’lerin iyi yatırımlar için gözlerini titizlikle ayarlamasına benzer şekilde, içerik finans mühendisliği ekibi’S Charter, Netflix’in eylemlerimizden yatırım yapmalarına, izlemesine ve öğrenmesine yardımcı olmaktır, böylece gelecekte sürekli daha iyi yatırımlar yapmalıyız.
Etkinliği kucakla
Mühendislik açısından, her finansal uygulama bir mikro hizmet olarak modellenir ve uygulanır. Netflix, dağıtılmış yönetişimi benimser ve şirket ölçeklendikçe veri soyutlaması ve hız arasında doğru dengeyi elde etmeye yardımcı olan uygulamalara mikro hizmet odaklı bir yaklaşımı teşvik eder. Basit bir dünyada, hizmetler HTTP aracılığıyla iyi etkileşime girebilir, ancak ölçeklendikçe, potansiyel olarak bölünmüş bir beyin/duruma yol açabilecek ve kullanılabilirliği bozabilecek karmaşık, istek tabanlı etkileşimlerin karmaşık bir grafiğine dönüşürler.
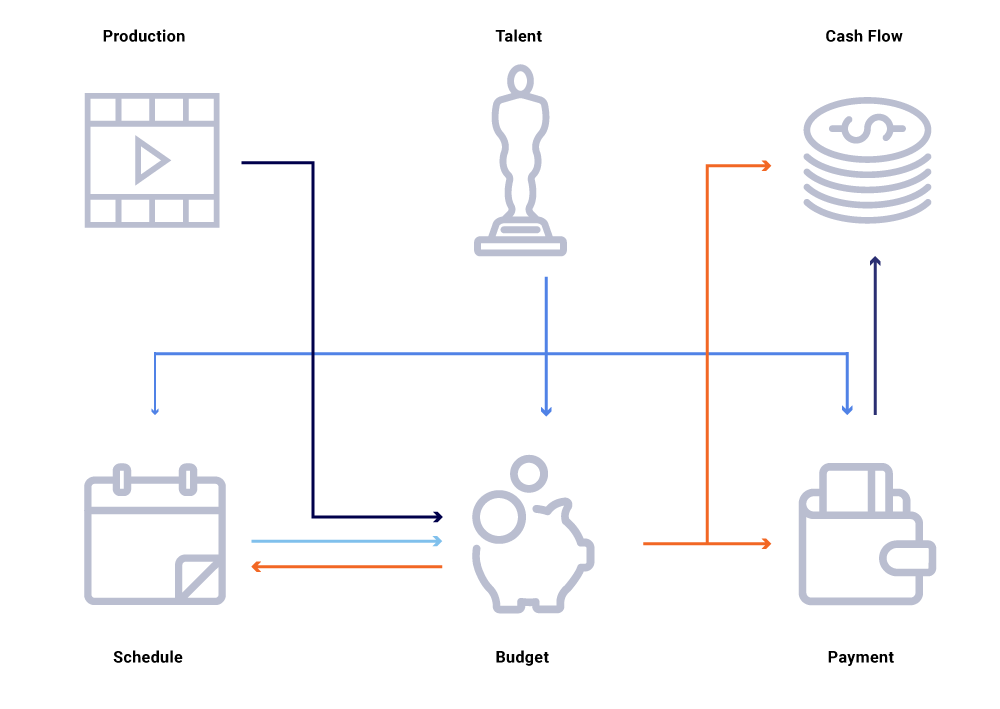
Yukarıdaki ilgili varlıkların grafiğinde, bir gösterinin üretim tarihinde bir değişikliği düşünün. Bu, nakit akışı projelerini, yetenek ödemelerini, yıl için bütçeleri vb. Genellikle bir mikro hizmet mimarisinde, başarısızlık yüzdesi kabul edilebilir. Bununla birlikte, mikro hizmetlerden herhangi birinde bir arıza, içerik finansmanı mühendisliği çağrısında bulunulacak, çok sayıda hesaplamanın senkronize olmasına neden olacak ve verilerin milyonlarca dolar kapalı olmasına neden olabilir. Ayrıca, çağrı grafiğinin ortaya çıkması ve iş sorularını etkili bir şekilde izlemeye ve cevaplamaya çalışırken kör noktalara neden olduğu gibi kullanılabilirlik sorunlarına yol açacaktır, örneğin: Nakit akışı projeksiyonları neden lansman programımızdan sapıyor? Cari yılın tahminleri neden aktif gelişmede olan şovları dikkate almıyor?? Maliyet raporlarımızın yukarı akış değişikliklerini doğru bir şekilde yansıtmasını ne zaman bekleyebiliriz??
Hizmet etkileşimlerini, bir dizi eşzamanlı isteklerin aksine, olay değişimlerinin akışı olarak yeniden düşünmek, bize doğası gereği eşzamansız olan altyapı oluşturmaya. Ayrılmayı teşvik eder ve dağıtılmış işlemlerin bir ağında birinci sınıf bir vatandaş olarak izlenebilirlik sağlar. Etkinlikler tetikleyicilerden ve güncellemelerden çok daha fazlası. Tüm sistem durumunu yeniden inşa edebileceğimiz değişmez akış haline gelirler.
Bir yayın/abone modeline doğru ilerlemek, her hizmetin olaylarını olay olarak yayınlamasını sağlar ve daha sonra dünya durumunu ayarlaması gereken başka bir ilgi hizmeti tarafından tüketilebilir. Böyle bir model, hizmetlerin durum değişikliklerine göre senkronize olup olmadığını ve senkronize olmaları ne kadar süre önce izlememizi sağlar. Bu bilgiler, bağımlı hizmetlerin büyük bir grafiğini kullanırken son derece güçlüdür. Olay tabanlı iletişim ve merkezi olmayan tüketim, genellikle büyük senkron çağrı grafiklerinde gördüğümüz sorunların üstesinden gelmemize yardımcı olur (yukarıda belirtildiği gibi).
Netflix, etkinlik, mesajlaşma ve akış işleme ihtiyaçları için fiili standart olarak Apache Kafka ® ‘yı kucaklar. Kafka, tüm noktadan noktaya ve Netflix Studio Wide Communications için bir köprü görevi görür. Netflix’teki işletim sistemleri için gerekli olan yüksek dayanıklılık ve doğrusal olarak ölçeklenebilir, çok kiracılı mimariyi sağlar. Şirket içi Kafka, bir hizmet sunumu olarak arıza toleransı, gözlemlenebilirlik, çok bölgeli dağıtımlar ve self servis sağlar. Bu, tüm mikro hizmet ekosistemimizin anlamlı olayları kolayca üretmesini ve tüketmesini ve asenkron iletişimin gücünü ortaya çıkarmasını kolaylaştırır.
Netflix Studio ekosisteminde tipik bir mesaj değişimi şuna benziyor:
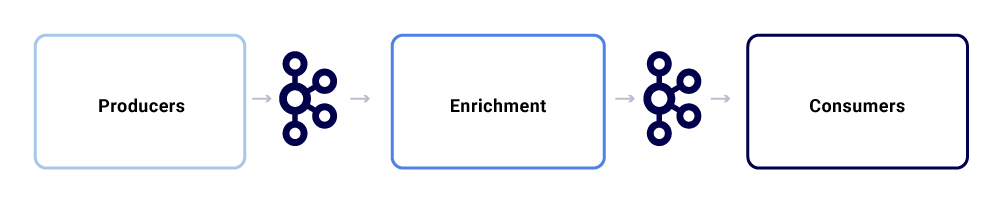
Onları üç ana alt bileşen olarak parçalayabiliriz.
Üreticiler
Bir üretici, tüm durumunu yayınlamak veya iç durumunun kritik bir parçasının belirli bir varlık için değiştiğini ima eden herhangi bir sistem olabilir. Yükün dışında, bir etkinliğin normalleştirilmiş bir formata uyması gerekir, bu da izlemeyi ve anlamayı kolaylaştırır. Bu biçim şunları içerir:
- UUID: Evrensel olarak benzersiz tanımlayıcı
- Tip: Oluşturma, okuma, güncelleme veya sil (crud) türlerinden biri
- TS: Etkinliğin zaman damgası
Veri Yakalamasını Değiştir (CDC) Araçları, veritabanı değişikliklerinden olayları elde eden başka bir olay üreticisi kategorisidir. Bu, birden fazla tüketici için veritabanı değişikliklerini kullanılabilir hale getirmek istediğinizde yararlı olabilir. Bu modeli de aynı verileri veri merkezlerinde çoğaltmak için kullanıyoruz (tek ana veritabanları için). Bir örnek, MySQL’de Elasticsearch veya Apache Solr ™ ‘da dizine eklenmesi gereken verilerimizdir. CDC kullanmanın yararı, kaynak uygulamaya ek yük getirmemesidir.
CDC olayları için, olay formatındaki tür alanı, ilgili lavaboların gerektirdiği şekilde olayları uyarlamayı ve dönüştürmeyi kolaylaştırır.
Zenginleştiriciler
Kafka’da veri var olduğunda, ona çeşitli tüketim modelleri uygulanabilir. Etkinlikler, sistem hesaplamaları için tetikleyiciler, gerçek zamana yakın iletişim için yük aktarımı ve verilerin bellek içi görüşlerini zenginleştirmek ve gerçekleştirmek için ipuçları dahil olmak üzere birçok yönden kullanılır.
Veri zenginleştirmesi, mikro hizmetlerin bir veri kümesinin tam görünümüne ihtiyaç duyduğu yerlerde giderek yaygınlaşıyor, ancak verilerin bir kısmı başka bir hizmetten geliyor’S veri kümesi. Birleştirilmiş bir veri kümesi, sorgu performansını artırmak veya toplu verilerin gerçek zamanlı görünümünü sağlamak için yararlı olabilir. Etkinlik verilerini zenginleştirmek için tüketiciler Kafka’dan gelen verileri okur ve daha sonra diğer Kafka konularına beslenen birleştirilmiş veri kümesini oluşturmak için diğer hizmetleri (GRPC ve GraphQL içeren yöntemleri kullanarak) çağırır.
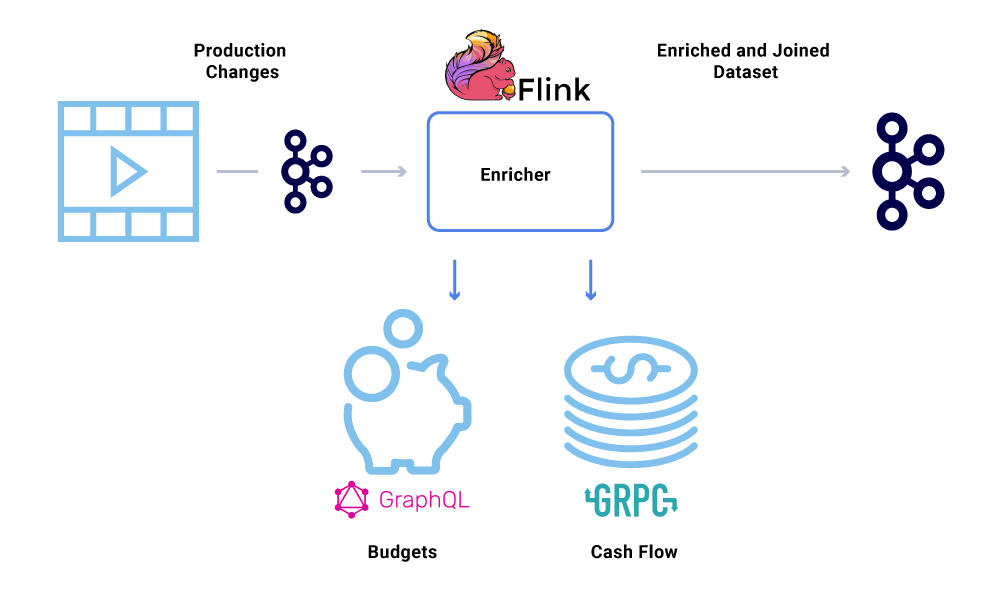
Zenginleştirme, hayranları yapmaktan ve veri kümelerini gerçekleştirmekten sorumlu olan ayrı bir mikro hizmet olarak çalıştırılabilir. Pencere, oturum ve durum yönetimi gibi daha karmaşık işlem yapmak istediğimiz durumlar var. Bu gibi durumlarda, iş mantığı oluşturmak için Kafka’nın üstünde olgun bir akış işleme motorunun kullanılması önerilir. Netflix’te akış işlemesi yapmak için Apache Flink® ve RocksDB’yi kullanıyoruz. Biz’Ayrıca benzer amaçlar için KSQLDB’yi de düşünmek.
Etkinliklerin Siparişi
Bir finansal veri kümesindeki temel gereksinimlerden biri, olayların sıkı sırasıdır. Kafka, bunu başarmamıza yardımcı olur, anahtarlı mesajlar göndererek. Aynı anahtarla gönderilen herhangi bir olay veya mesaj, aynı bölüme gönderildikleri için sipariş vermeyi garanti edecektir. Ancak, üreticiler yine de olayların sırasını bozabilir.
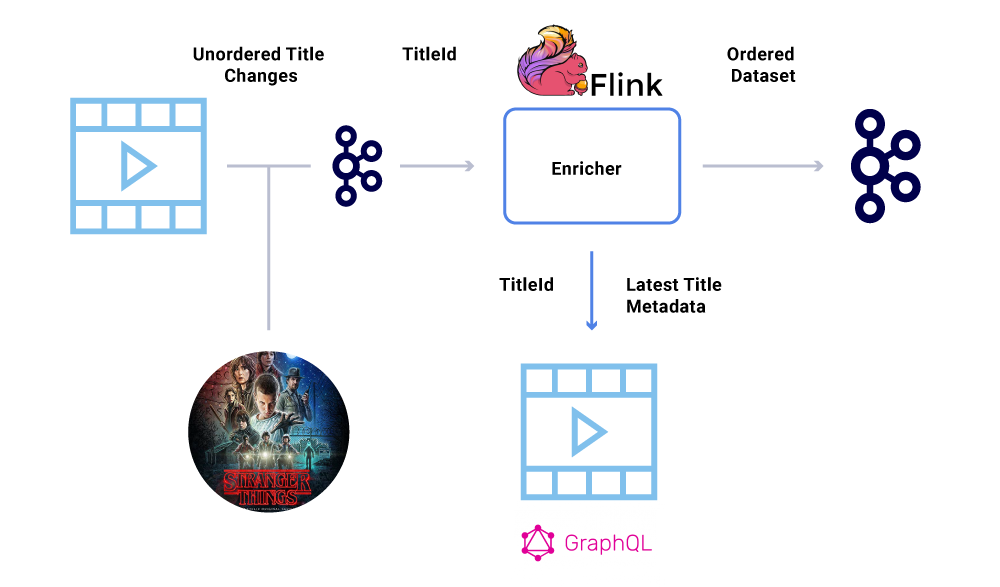
Örneğin, lansman tarihi “Stranger Things” başlangıçta Temmuz’dan Haziran’a taşındı, ancak Haziran’dan Temmuz’a kadar geri döndü. Çeşitli nedenlerden dolayı, bu olaylar Kafka’ya yanlış sırayla yazılabilir (yapımcı, üretici kodunda eşzamanlılık hatası olan Kafka’ya ulaşmaya çalıştığında ağ zaman aşımı, vb.). Hıçkırık siparişi çeşitli finansal hesaplamaları büyük ölçüde etkileyebilir.
Bu senaryoyu atlatmak için üreticiler, Kafka mesajındaki tam yükü değil, yalnızca değişen varlığın birincil kimliğini göndermeye teşvik edilir. Zenginleştirme işlemi (yukarıdaki bölümde açıklanmıştır), en güncel durum/yük yükünü elde etmek için varlığın kimliği ile kaynak hizmetini sorgular, böylece sıralı sorunu atlatmanın zarif bir yolunu sağlar. Buna şöyleyiz Gecikmeli Materyalizasyon, ve sipariş edilen veri kümelerini garanti ediyor.
Tüketiciler
Kafka konularından okuyan tüketen mikro hizmetlerin çoğunu uygulamak için Spring Boot’u kullanıyoruz. Spring Boot, tüketimi sorunsuz hale getiren ve verilerin tüketimi ve süzülme için ek açıklamaları bağlamanın kolay yollarını sağlayan Spring Kafka konektörleri adı verilen harika yerleşik Kafka Tüketicileri sunuyor.
Have olduğumuz verilerin bir yönü’henüz tartışıldı sözleşmeler. Etkinlik akışlarını kullanımımızı ölçeklendirirken, bazıları çok sayıda uygulama tarafından tüketilen çeşitli bir veri kümesi grubu ile sonuçlanıyoruz. Bu durumlarda, çıktı üzerinde bir şema tanımlamak idealdir ve geriye dönük uyumluluğu sağlamaya yardımcı olur. Bunu yapmak için, veri akışlarını sürümleme için şematik akışlarımızı oluşturmak üzere Confluent Şema Kayıt Defteri ve Apache AVRO ™ ‘dan yararlanıyoruz.
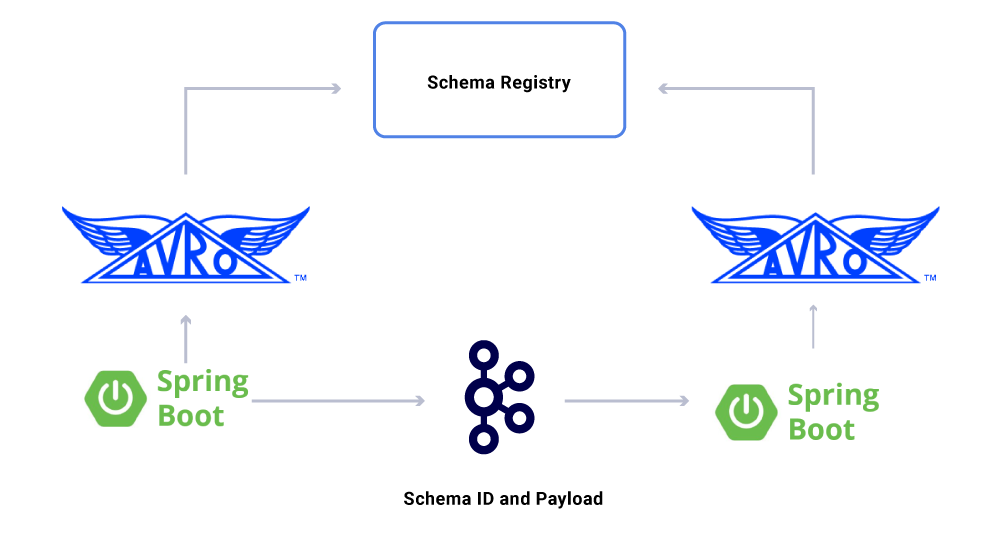
Özel mikro hizmet tüketicilerine ek olarak, verileri daha fazla analiz için çeşitli mağazalara dizine ekleyen CDC lavabolarımız da var. Bunlar arasında anahtar kelime araması için elasticsearch, denetim için Apache Hive ™ ve daha fazla akış aşağı işlem için Kafka’nın kendisi. Bu tür lavabolar için yük, kimlik alanını birincil anahtar olarak kullanarak Kafka mesajından doğrudan türetilmiştir ve CRUD işlemlerini tanımlamak için tür.
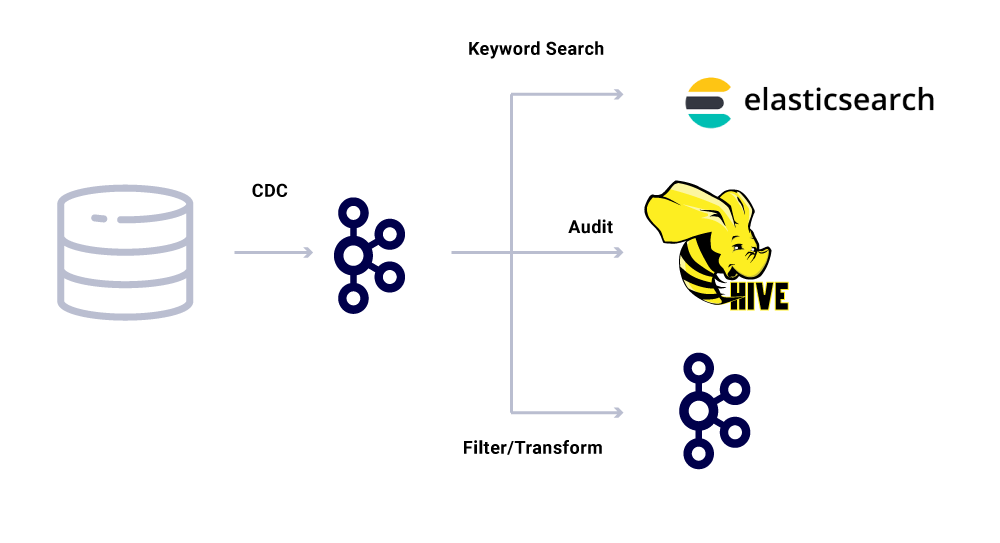
Mesaj Teslimat Garantileri
Dağıtılmış bir sistemde teslimatı tam olarak garanti etmek, ilgili karmaşıklıklar ve çok sayıda hareketli parça nedeniyle önemsizdir. Tüketiciler, herhangi bir potansiyel altyapı ve üretici aksiliklerini açıklamak için idempotent davranışlara sahip olmalıdır.
Uygulamaların idempotent olmasına rağmen, zaten işlenmiş mesajlar için ağır işlemleri tekrarlamamalıdırlar. Bunu sağlamanın popüler bir yolu, bir hizmet tarafından dağıtılmış bir önbellekte tüketilen mesajların UUID’ini makul bir son kullanma ile takip etmektir (Hizmet Düzeyi Anlaşmalarına (SLA) göre tanımlanır. Expiry aralıklarında aynı UUID ile karşılaşıldığında, işleme atlanır.
Flink’te işleme, bu garantiyi dahili rocksdb tabanlı durum yönetimini kullanarak sağlar ve anahtar mesajın UUID’sidir. Bunu tamamen Kafka’yı kullanarak yapmak istiyorsanız, Kafka Streams da bunu yapmanın bir yolunu sunar. Spring Boot’a dayalı uygulamaları tüketmek, bunu başarmak için evcache kullanın.
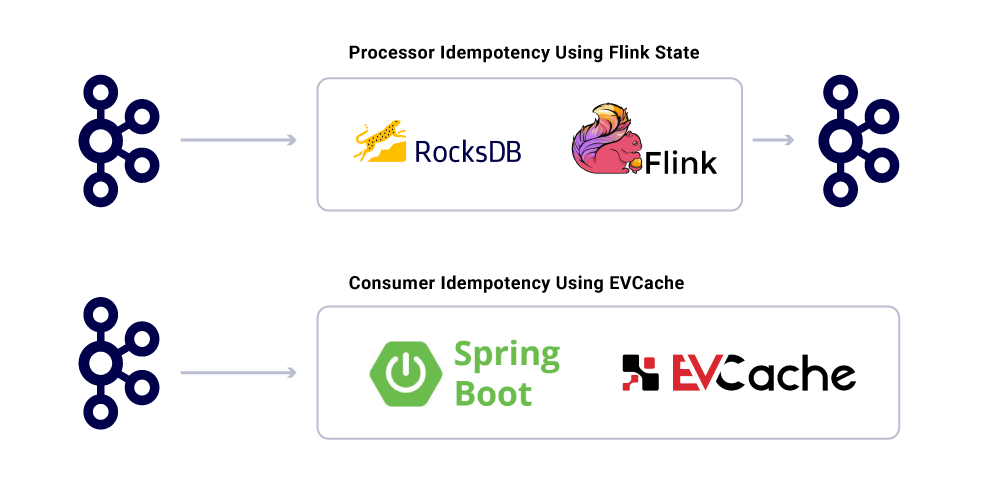
Altyapı hizmet seviyelerinin izlenmesi
BT’Netflix’in altyapısında hizmet seviyeleri hakkında gerçek zamanlı bir görünüm elde etmesi çok önemli. Netflix, metrikleri yayınladığımız ve görselleştirdiğimiz boyutsal zaman serisi verilerini yönetmek için Atlas yazdı. Yapımcılar, işlemciler ve tüketiciler tarafından yayınlanan çeşitli metrikleri kullanıyoruz, tüm altyapının gerçek zamanlı bir resmini oluşturmamıza yardımcı olmak için.
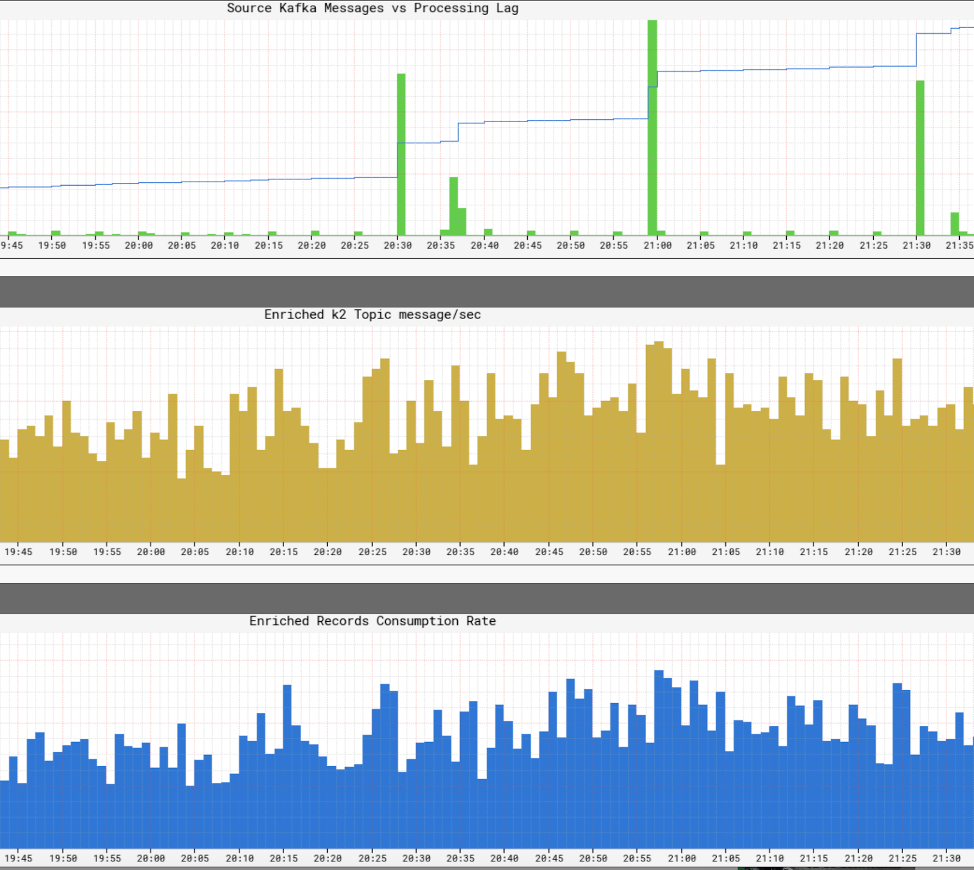
İzlediğimiz temel yönlerden bazıları:
- Tazelik sla
- Tüm lavabolara ulaşana kadar bir etkinliğin üretiminden uçtan uca zaman nedir??
- Her tüketici için işleme gecikmesi nedir?
- Ne kadar büyük bir yük gönderebiliriz?
- Verileri sıkıştırmalı mıyız?
- Kaynaklarımızı etkili bir şekilde kullanıyor muyuz?
- Daha hızlı tüketebilir miyiz?
- Durumumuz için bir kontrol noktası oluşturabilir ve başarısızlık durumunda devam edebilir miyiz??
- Firehose etkinliğine ayak uyduramıyorsak, başvurumuzu çökertmeden karşılık gelen kaynaklara geri basınç uygulayabilir miyiz?
- Olay patlamalarıyla nasıl başa çıkıyoruz?
- SLA’yı karşılamak için yeterince sağlanıyor muyuz?
Özet
Netflix Studio Productions and Finance Ekibi, Mimar Sistemlerinin Yolu olarak Dağıtılmış Yönetişimi Kucaklıyor. Kafka’yı, sistem durumunu kaydetmenin ve türetmenin değişmez bir yolu olan etkinliklerle çalışmak için tercih edilen platformumuz olarak kullanıyoruz. Kafka, operasyonları organik olarak ölçeklendirmemize yardımcı olurken, altyapımızda daha yüksek düzeyde görünürlük ve ayrıştırma elde etmemize yardımcı oldu. Netflix Studio Altyapısı’nı devrim yaratmanın merkezinde ve onunla birlikte film endüstrisi.
Daha fazlası ile ilgilenmek?
Eğer sen’D Daha fazlasını bilmek isterim, Kafka Zirvesi San Francisco Sunumumun Kayıt ve Slaytlarını Görüntüleme – Netflix Orijinal!
Netflix: Apache Kafka Milyonlarca’dan Verileri İstihbarat’a Nasıl Dönüştür?
Netflix 2020’de içerik üretimine 16 milyar dolar harcadı. Ocak 2021’de Netflix Mobil Uygulaması (iOS ve Android) 19 milyon kez indirildi ve bir ay sonra şirket 203’e ulaştığını açıkladı.Dünya çapında 66 milyon abone. BT’Şirketin topladığı ve süreçlerin ölçüsünün büyük olduğunu varsaymak güvenli. Soru –
Netflix, kritik iş kararları almak için milyarlarca veri kaydını ve olayını nasıl işliyor??
16 milyar dolarlık yıllık içerik bütçesi ile Netflix Aren’de karar vericiler’Sezgiye dayalı içerikle ilgili kararlar alacak. Bunun yerine, içerik küratörleri, abone davranışı, kullanıcı içeriği tercihleri, içerik üretim maliyetleri, çalışan içerik türleri vb. Hakkında büyük miktarlarda veri anlamak için en yeni teknolojiyi kullanır. Bu liste devam ediyor.
Netflix kullanıcıları ortalama 3 harcıyor.Platformlarında günde 2 saat ve Netflix tarafından en son önerilerle sürekli olarak beslenir’s tescilli Tavsiye Motoru. Bu, abone karmaşasının düşük olmasını sağlar ve yeni aboneleri kaydolmaya teşvik eder. Veri odaklı içerik teslimi, bunun önünde ve ortasındadır.
Öyleyse, bir veri işleme perspektifinden kaputun altında yatan şey?
Başka bir deyişle, Netflix veri odaklı karar almayı bu kadar büyük bir ölçekte nasıl oluşturdu?? 203 milyon abonenin kullanıcı davranışını nasıl anlamlandırıyor??
Netflix, Keystone Veri Boru Hattı dediği şeyi kullanır. 2016 yılında, bu boru hattı günde 500 milyar etkinlik işliyordu. Bu olaylar arasında hata günlükleri, kullanıcı görüntüleme faaliyetleri, UI etkinlikleri, sorun giderme olayları ve diğer birçok değerli veri kümesi vardı.
Netflix’e göre, teknoloji blogunda yayınlandığı gibi:
Keystone Boru Hattı, hem parti hem de akış işlemesi için birleştirilmiş bir etkinlik yayınlama, toplama ve yönlendirme altyapısıdır.
Kafka kümeleri, Netflix’teki Keystone Veri Boru Hattı’nın temel bir parçasıdır. 2016 yılında Netflix Boru Hattı, günde milyarlarca mesajı işlemek için 36 Kafka kümesi kullandı.
Peki, Apache Kafka nedir? Ve neden bu kadar popüler hale geldi?
Apache Kafka, yüksek miktarda gerçek zamanlı veri yayan uygulamaların geliştirilmesini sağlayan açık kaynaklı bir akış platformudur. Başlangıçta LinkedIn’deki Geniuses tarafından inşa edildi ve şimdi Netflix, Pinterest ve Airbnb’de birkaç isim vermek için kullanıldı.
Kafka özellikle dört şey yapar:
- Uygulamaların veri veya olay akışlarında yayınlamasını veya abone olmasını sağlar
- Veri kayıtlarını doğru bir şekilde depolar ve oldukça hataya toleranslıdır
- Gerçek zamanlı, yüksek hacimli veri işleme yeteneğine sahiptir.
- Herhangi bir performans sorunu olmadan günde trilyonlarca veri kaydı alabilir ve işleyebilir
Yazılım geliştirme ekipleri Kafka’dan yararlanabilir’Aşağıdaki API’lerle S Yetenekleri:
- Üretici API: Bu API, belirli bir Kafka konusuna bir veri akışı yayınlamasını bir mikro hizmet veya uygulamayı etkinleştirir. Kafka konusu, veri ve olay kayıtlarını gerçekleştikleri sırayla depolayan bir günlüktir.
- Tüketici API: Bu API, bir uygulamanın bir Kafka konusundan veri akışlarına abone olmasını sağlar. Tüketici API’sını kullanarak uygulamalar, belirtilen uygulamaya girdi olarak hizmet edecek veri akışını yutabilir ve işleyebilir.
- Streams API: Bu API, gelişmiş veriler ve etkinlik akışı uygulamaları için kritik öneme sahiptir. Esasen, çeşitli Kafka konularından veri akışlarını tüketir ve bunu gerektiği gibi işleyebilir veya dönüştürebilir. İşlem sonrası, bu veri akışı, aşağı yönde kullanılacak ve/veya mevcut bir konuyu dönüştürmek için başka bir Kafka konusuna yayınlanır.
- Konnektör API: Modern uygulamalarda, üreticileri veya tüketicileri yeniden kullanmaya ve bir veri kaynağını otomatik olarak bir Kafka kümesine entegre etmeye ihtiyaç vardır. Kafka Connect bunu gereksiz hale getirir Kafka’yı harici sistemlere bağlar.
Kafka’nın temel avantajları
Kafka web sitesine göre, tüm Fortune 100 şirketlerinin% 80’i Kafka’yı kullanıyor. Bunun en büyük nedenlerinden biri, görev açısından kritik uygulamalara iyi uymasıdır.
Büyük şirketler Kafka’yı aşağıdaki nedenlerle kullanıyor:
- Veri akışlarının ve sistemlerinin kolaylıkla ayrılmasına izin verir
- Dağıtılmak üzere tasarlanmıştır, esnek ve hataya toleranslı
- Kafka’nın yatay ölçeklenebilirliği en büyük avantajlarından biridir. Saniyede 100’lü küme ve milyonlarca mesaja ölçeklenebilir
- Yüksek performanslı gerçek zamanlı veri akışı olan, büyük ölçekli, veri odaklı uygulamalarda kritik bir ihtiyaç sağlar
Kafka’nın veri işlemeyi optimize etmek için kullanıldığı yollar
Kafka, aşağıdakiler dahil ancak bunlarla sınırlı olmamak üzere, endüstriler arasında çeşitli amaçlar için kullanılmaktadır
- Gerçek Zamanlı Veri İşleme: Kafka, teknoloji şirketlerinde kullanımına ek olarak, yüksek hacimli verilerin çok sayıda IoT cihazından ve sensörden geldiği imalat endüstrisinde gerçek zamanlı veri işlemenin ayrılmaz bir parçasıdır
- Ölçekte web sitesi izleme: Kafka, yüksek trafikli web sitelerinde kullanıcı davranışını ve site etkinliğini izlemek için kullanılır. Gerçek zamanlı izleme, işleme, Hadoop ile bağlantı kurma ve çevrimdışı veri ambarına yardımcı olur
- Anahtar metrikleri izleme: Kafka, farklı uygulamalardan verileri merkezi bir yemle toplamak için kullanılabileceğinden, yüksek hacimli operasyonel verilerin izlenmesini kolaylaştırır
- Günlük Toplama: Dağıtılmış tüketim hakkında netlik elde etmek için birden çok kaynaktan gelen verilerin bir günlüğe toplanmasına izin verir
- Mesajlaşma Sistemi: Büyük ölçekli mesaj işleme uygulamalarını otomatikleştirir
- Akış İşleme: Kafka konuları çeşitli aşamalarda boru hatlarının işlenmesinde ham veri olarak tüketildikten sonra, daha fazla tüketim veya işleme için toplanmış, zenginleştirilmiş veya başka bir şekilde yeni konulara dönüştürülür
- Sistem bağımlılıklarını kaldırma
- Entegrasyonlar Spark, Flink, Storm, Hadoop ve diğer büyük veri teknolojileri ile
Verileri işlemek için Kafka’yı kullanan şirketler
Çok yönlülüğü ve işlevselliği sonucunda Kafka, bazı dünya tarafından kullanılır’Çeşitli amaçlar için en hızlı büyüyen teknoloji şirketleri:
- Uber-talebi hesaplamak ve tahmin etmek ve gerginlik fiyatlandırmasını gerçek zamanlı olarak hesaplamak ve hesaplamak için bir kullanıcı, taksi ve seyahat verilerini gerçek zamanlı olarak toplayın
- LinkedIn-SPAM’ı önler ve gerçek zamanlı olarak daha iyi bağlantı önerileri yapmak için kullanıcı etkileşimlerini toplar
- Twitter – Fırtına Akışı İşleme Altyapısının bir parçası
- Spotify – günlük dağıtım sisteminin bir parçası
- Pinterest – Günlük toplama boru hattının bir parçası
- Airbnb – Etkinlik boru hattı, istisna izleme vb.
- Cisco – OpenSoc için (Güvenlik Operasyon Merkezi)
Liyakat grubu’Kafka’daki uzmanlık
Merit Group’ta bazı dünyayla çalışıyoruz’W Wilmington, Dow Jones, Glenigan ve Haymarket gibi önde gelen B2B istihbarat şirketleri. Veri ve Mühendislik Ekiplerimiz, veri ürünleri ve iş zekası araçları oluşturmak için müşterilerimizle yakın çalışıyor. Çalışmalarımız, müşterilerimizin yüksek büyüme fırsatlarını belirlemelerine yardımcı olarak iş büyümesini doğrudan etkiler.
Özel hizmetlerimiz arasında yüksek hacimli veri toplama, AI ve ML kullanan veri dönüşümü, Web İzleme ve Özelleştirilmiş Uygulama Geliştirme.
Ekibimiz ayrıca, gerçek zamanlı veri akışı ve veri işleme uygulamaları oluşturma konusunda derin uzmanlık getiriyor. Kafka’daki uzmanlığımız bu bağlamda özellikle yararlıdır.
Пбастника confluent
Sistem durumunu kaydeden ve türeten mimar sistemlere Netflix, Apache Kafka’dan yararlanır ve yönetişim. Nitin S. Organik olarak operasyonları ölçeklendirirken bunun altyapılarında görünürlüğe ve ayrışmaya ulaşmalarına nasıl yardımcı olur: https: // lnkd./gfxaa6g
Netflix dağıtılmış akış için Kafka’yı nasıl kullanır?
birleşmiş.io
- Копировать
Mümin, kocası, 5’in babası, BT altyapısı ve hizmet yöneticisi, takım lideri, geliştirici.
Netflix, etkinlik kaynak kullanımı, MQTT ve Alpakka-Kafka ile güvenilir, ölçeklenebilir bir platform oluşturuyor
Netflix kısa süre önce MQTT tabanlı bir etkinlik kaynağı uygulaması kullanarak güvenilir bir cihaz yönetim platformunu nasıl oluşturduğunu detaylandıran bir blog yazısı yayınladı. Çözümünü ölçeklendirmek için Netflix.
Netflix’in Cihaz Yönetim Platformu, uygulamalarının otomatik olarak test edilmesi için kullanılan donanım cihazlarını yöneten sistemdir. Netflix mühendisleri Benson Ma ve Alok Ahuja, platformun yaşadığı yolculuğu anlatıyor:
Kafka akışları işlemenin doğru olması zor olabilir. (. ) Neyse ki, Akka Streams ve Alpakka-Kafka tarafından sağlanan ilkeller, bu çözümleri geliştirirken ve bu çözümleri sürdürmede geliştiricinin verimliliğini ölçeklendirirken sahip olduğumuz iş iş akışlarıyla eşleşen akış çözümleri oluşturmamıza izin vererek bizi tam olarak başarmamızı sağlar. Alpakka-Kafka merkezli işlemci yerinde (. ), Cihaz Yönetim Platformu içinde doğru ve güvenilir cihaz durumunun toplanmasını sağlamanın anahtarı olan kontrol düzleminin tüketici tarafında arıza toleransını sağladık.
(. ) Platformun güvenilirliği ve kontrol düzlemi, MQTT taşımacılığı, kimlik doğrulama ve yetkilendirme ve sistem izleme dahil olmak üzere çeşitli alanlarda yapılan önemli çalışmalara dayanmaktadır. (. ) Bu çalışmanın bir sonucu olarak, cihaz yönetim platformunun sistemlerimize daha fazla cihazda daha fazla cihazda bulunduğumuz için zaman içinde artan iş yüklerini ölçeklendirmeye devam etmesini bekleyebiliriz.
Aşağıdaki diyagram mimariyi tasvir etmektedir.

Kaynak: https: // netflixtechblog.com/yönlendirilebilir cihaz-platform-platform-4f86230ca623
Yerel referans otomasyon ortamı (RAE) gömülü bilgisayar, test altındaki birkaç cihaza bağlanır (DUT). Yerel Kayıt Hizmeti, RAE’deki tüm bağlı cihazlar hakkında bilgi algılamak, işe almak ve korumaktan sorumludur. Aygıt özellikleri ve özellikleri zaman içinde değiştikçe, bu değişiklikleri yerel kayıt defterine kaydeder ve aynı anda bulut tabanlı bir kontrol düzleminde yayınlanır. Öznitelik değişikliklerine ek olarak, yerel kayıt defteri, cihaz kaydının tam bir anlık görüntüsünü düzenli aralıklarla yayınlar. Bu kontrol noktası olayları, kaçırılan güncellemelere karşı korumayı korurken veri akışının tüketicileri tarafından daha hızlı durum yeniden yapılandırılmasını sağlar.
Güncellemeler MQTT kullanarak buluta yayınlandı. MQTT, Nesnelerin İnterneti (IoT) için bir Oasis standart mesajlaşma protokolüdür. Uzak cihazları küçük bir kod ayak izi ve minimal ağ bant genişliği ile bağlamak için ideal olan hafif ama güvenilir bir yayın/abone mesajlaşma taşımacılığıdır. MQTT broker, tüm mesajları almaktan, filtrelemekten ve bunları abone olan istemcilere buna göre göndermekten sorumludur.
Netflix, Organizasyon boyunca Apache Kafka’yı kullanıyor. Sonuç olarak, bir köprü MQTT mesajlarını Kafka Records’a dönüştürür. Kayıt anahtarını, mesajın atandığı MQTT konusuna ayarlar. Ma ve Ahuja, “MQTT’de yayınlanan cihaz güncellemeleri şunları içerdiğinden cihaz_session_id Konuda, belirli bir cihaz oturumu için tüm cihaz bilgileri güncellemeleri aynı Kafka bölümünde etkili bir şekilde görünecek ve böylece bize tüketim için iyi tanımlanmış bir mesaj sırası verecektir.”
Bulut Kayıt Defteri, yayınlanan mesajları yutur, işler ve malzemelendirilmiş verileri hamamböceği tarafından desteklenen bir veri deposuna iter. Hamproachdb, Newsql adlı bir RDBMS sistemlerinin bir uygulamasıdır. Ma ve Ahuja Netflix’in seçimini açıklar:
SQL özellikleri sunduğundan beri RockroachDB, destek veri deposu olarak seçilir ve cihaz kayıtları için veri modelimiz normalleştirildi. Buna ek olarak, diğer SQL mağazalarından farklı olarak, POPROACHDB, Bulut Kayıt Defterinin Cihaz Yönetim Platformu’na yerleştirilen cihaz sayısıyla ölçeklendirme yeteneğiyle ilgili endişelerimizi ele alan yatay olarak ölçeklenebilir olacak şekilde tasarlanmıştır.
Aşağıdaki diyagram, bulut kayıt defterini içeren Kafka işleme boru hattını göstermektedir.

Kaynak: https: // netflixtechblog.com/yönlendirilebilir cihaz-platform-platform-4f86230ca623
Netflix, yukarıda tasvir edilen akış işleme boru hatlarını uygulamak için birçok çerçeveyi düşündü. Bu çerçeveler Kafka Streams, Spring Kafkalistener, Project Reactor ve Flink’i içerir. Sonunda Alpak-Kafka’yı seçti. Bu seçimin nedeni, Alpakka-Kafka’nın, otomatik geri basınç desteği ve akış denetimi de dahil olmak üzere “akış işleme üzerinde ince taneli kontrol ile birlikte yay önyükleme entegrasyonu sağlamasıdır.”Ayrıca, Ma ve Ahuja’ya göre, Akka ve Alpakka-Kafka alternatiflerden daha hafiftir ve daha olgun oldukları için zaman içindeki bakım maliyetleri daha düşük olacaktır.
Alpakka-Kafka merkezli uygulama, daha erken bir bahar Kafkalistener tabanlı bir zahmetin yerini aldı. Yeni üretim uygulamasında ölçülen metrikler, Alpakka-Kafka’nın yerli geri basınç desteğinin Kafka tüketimini dinamik olarak ölçeklendirebileceğini ortaya koyuyor. Kafkalistener’ın aksine, Alpakka-Kafka, yetersiz veya aşırı tüketmez Kafka Mesajları. Ayrıca, sürümden sonra maksimum tüketici gecikmesi değerlerinde bir düşüş, Alpakka-Kafka’nın ve Akka’nın akış özelliklerinin ani mesaj yükleri karşısında bile iyi performans gösterdiğini ortaya koydu.