Использует ли Netflix kafka?
Показ Апач Кафка в Netflix Studio и Finance World
Краткое содержание:
В Netflix большинство приложений используют клиентскую библиотеку Java для производства данных в трубопровод Keystone. Трубопровод состоит из фронтальных кластеров Kafka, ответственных за сбор и буферизацию данных, а также потребительские кластеры Kafka, содержащие темы для потребителей в реальном времени. Netflix управляет 36 кластерами Kafka, которые ежедневно обрабатывают более 700 миллиардов сообщений. Для достижения доставки без потерь трубопровод допускает уровень потери данных менее 0.01%. Производители и брокеры настроены для обеспечения доступности и хорошего опыта пользователя.
Ключевые моменты:
- Приложения Netflix Используйте клиентскую библиотеку Java для производства данных в Keystone Pipeline
- Несколько производителей кафки существуют в каждом экземпляре приложения
- Fronting Kafka Clusters собирают и буферируют сообщения
- Кластеры потребителей Кафки содержат темы для потребителей в реальном времени
- Netflix управляет 36 кластерами Kafka с более чем 700 миллиардами сообщений в день
- Уровень потери данных меньше 0.01%
- Производители и брокеры настроены для обеспечения доступности
- Производители используют динамическую конфигурацию для маршрутизации темы и изоляции раковины
- Приложения, не связанные с Java, могут отправлять события в конечные точки REST Keystone
- Заказ сообщений устанавливается в партийной обработке или уровне маршрутизации
Вопросы:
- Как приложения Netflix создают данные в трубопровод Keystone?
- Каковы роли фронта?
- Какие типы кластеров кафки существуют в трубопроводе Keystone?
- Сколько кластеров Kafka работает Netflix?
- Какова средняя скорость приема данных для Netflix?
- Какова текущая версия Кафки, используемой Netflix?
- Как Netflix достигает доставки без потерь в трубопроводе?
- Какова конфигурация для производителей и брокеров для обеспечения доступности?
- Как поддерживается заказ сообщения?
- Почему клиентские приложения не потребляют непосредственно от фронта кафки?
- Какие проблемы возникают при запуске кафки в облаке?
- Как репликация влияет на доступность Кафки?
- Что было сделано Netflix для устранения инцидентов и поддержания стабильности кластера?
- Что такое стратегия развертывания Netflix для кластеров Kafka?
Большинство приложений Netflix используют клиентскую библиотеку Java для производства данных в трубопровод Keystone. У каждого экземпляра приложения есть несколько производителей кафки.
Fronting Kafka Clusters собирают и буферируют сообщения от производителей. Они служат шлюзом для инъекции сообщений.
Трубопровод Keystone состоит из фронталов кластеров Kafka и потребителей Kafka Clasters.
Netflix работает 36 кластеров Kafka.
Netflix принимает более 700 миллиардов сообщений в день.
Netflix переходит от Kafka версии 0.8.2.От 1 до 0.9.0.1.
Учет огромного объема данных, Netflix работал с командами, чтобы принять приемлемый объем потери данных, что приводит к ежедневной частоте потери данных менее 0.01%.
Производители и брокеры настроены с «Acks = 1», Block.на.буфер.полный = false »и« нечистый.лидер.выборы.inable = true “.
Производители не используют ключевые сообщения, а упорядочение сообщений восстанавливается на уровне партийной обработки или уровне маршрутизации.
Клиентские приложения не разрешают напрямую потреблять из фронта кафки, чтобы обеспечить предсказуемую нагрузку и стабильность.
Запуск kafka в облаке создает такие проблемы, как непредсказуемый экземпляр жизненного цикла, переходные сетевые проблемы и выбросы, вызывающие проблемы с производительностью.
Репликация улучшает доступность, но выбросный брокер может вызвать каскадные эффекты и падение сообщений из -за задержки репликации и истощения буфера.
Netflix уменьшила состояние и сложность, внедренную выявление выбросов и разработал меры для быстрого восстановления после инцидентов.
Netflix благоприятствует нескольким небольшим кластерам Kafka по сравнению с одним гигантским кластером, чтобы снизить зависимости и улучшить стабильность.
Кафка внутри трубопровода Keystone
У нас есть два набора кластеров Kafka в трубопроводе Keystone:. Fronting Kafka кластеры несут ответственность за получение сообщений от производителей, которые практически каждый экземпляр приложения в Netflix. Их роли – сбор данных и буферизация для систем вниз по течению. Кластеры потребителей Кафки содержат подмножество тем, направленных Samza для потребителей в реальном времени.
В настоящее время мы управляем 36 кластерами Kafka, состоящими из более чем более 4000 экземпляров брокера как для выхода из Кафки, так и для потребителя Кафки. Более 700 миллиардов сообщений принимают в средний день. В настоящее время мы переходим из Kafka версии 0.8.2.От 1 до 0.9.0.1.
Принципы дизайна
Учитывая текущую архитектуру Kafka и наш огромный объем данных, для достижения без потерь доставки для нашего конвейера данных являются чрезмерными в AWS EC2. Учет этого, мы’В работал с командами, которые зависят от нашей инфраструктуры, чтобы получить приемлемый объем потери данных, при этом сбалансировать затраты. Мы’вел ежедневную скорость потери данных менее 0.01%. Метрики собираются для сброшенных сообщений, поэтому мы можем принять меры, если это необходимо.
Кейпновый трубопровод дает сообщения асинхронно, не блокируя приложения. В случае, если сообщение не может быть доставлено после повторных поисков, он будет отброшен производителем, чтобы обеспечить наличие приложения и хорошего пользовательского опыта. Вот почему мы выбрали следующую конфигурацию для нашего продюсера и брокера:
- Acks = 1
- блокировать.на.буфер.Полный = ложь
- нечистый.лидер.выборы.inable = true
Большинство приложений в Netflix используют нашу клиентскую библиотеку Java, чтобы произвести в Keystone Pipeline. В каждом экземпляре этих приложений существует несколько производителей кафки, каждый из которых производит в фронте кафки кластер для изоляции уровня раковины. Производители имеют гибкую маршрутизацию темы и конфигурацию погружения, которые обусловлены динамической конфигурацией, которую можно изменить во время выполнения без необходимости перезагрузки процесса применения. Это позволяет таким вещам, как перенаправление трафика и мигрирование тем по кластерам Kafka. Для приложений, не являющихся Java, они могут отправлять события в конечные точки REST Keystone, которые передают сообщения для фронталов кластеров Kafka.
Для большей гибкости производители не используют ключевые сообщения. Приблизительный заказ сообщений восстанавливается на уровне пакетной обработки (Hive / Elasticsearch) или уровне маршрутизации для потоковых потребителей.
Мы ставим стабильность наших фронтальных кластеров Kafka с высоким приоритетом, потому что они являются шлюзом для инъекции сообщений. Поэтому мы не позволяем клиентским приложениям напрямую потреблять из них, чтобы убедиться, что они имеют предсказуемую нагрузку.
Проблемы управления кафкой в облаке
Кафка была разработана с помощью центра обработки данных в качестве цели развертывания в LinkedIn. Мы приложили заметные усилия, чтобы заставить Кафку лучше работать в облаке.
В облаке экземпляры имеют непредсказуемый жизненный цикл и могут быть прекращены в любое время из-за проблем с оборудованием. Ожидаются проблемы с переходной сетью. Это не проблемы для без сохранения состояния, но представляют собой большую проблему для государственной службы, требующей зооукии и одного контроллера для координации.
Большинство наших проблем начинаются с выбросов брокеров. Выброс может быть вызван неравномерной рабочей нагрузкой, проблемами с оборудованием или его конкретной средой, например, шумных соседей из-за многоцелевого. Выбросный брокер может иметь медленные ответы на запросы или частые тайм -ауты TCP/ретрансмиссии. Производители, которые отправляют события такому брокеру. Другим фактором, способствующим истощению буфера, является то, что кафка 0.8.2 продюсер’T Поддержка тайм -аута для сообщений, ожидающих в буфере.
Кафка’S репликация улучшает доступность. Тем не менее, репликация приводит к взаимозависимости среди брокеров, где выброс может вызвать каскадный эффект. Если выброс замедляет репликацию, задержка репликации может нарастать и в конечном итоге заставит лидеров разделов читать с диска для обслуживания запросов на репликацию. Это замедляет пораженные брокеры и в конечном итоге приводит к тому, что производители отбрасывают сообщения из -за истощенного буфера, как объяснено в предыдущем случае.
В течение наших первых дней эксплуатации Kafka мы пережили инцидент, когда производители бросали значительное количество сообщений в кластер Kafka с сотнями случаев из -за проблемы с зоопером, в то время как мы мало что могли сделать. Такие проблемы отладки в маленьком временном окне с сотнями брокеров просто не реалистичны.
После инцидента были предприняты усилия по сокращению государственности и сложности для наших кластеров Кафки, обнаружения выбросов и найти способ быстро начать с чистого состояния, когда происходит инцидент.
Стратегия развертывания Кафки
Ниже приведены ключевые стратегии, которые мы использовали для развертывания кластеров Kafka:
- Благоприятствуем нескольким небольшим кластерам кафки, а не к одному гигантскому кластеру. Это снижает зависимости и улучшает стабильность.
- Реализуйте механизмы обнаружения выбросов для выявления и обработки проблемных брокеров.
- Разработайте меры по быстрому восстановлению от инцидентов и начало с чистого состояния.
Показ Апач Кафка в Netflix Studio и Finance World
Большинство приложений в Netflix используют нашу клиентскую библиотеку Java, чтобы произвести в Keystone Pipeline. В каждом экземпляре этих приложений существует несколько производителей кафки, каждый из которых производит в фронте кафки кластер для изоляции уровня раковины. Производители имеют гибкую маршрутизацию темы и конфигурацию погружения, которые обусловлены динамической конфигурацией, которую можно изменить во время выполнения без необходимости перезагрузки процесса применения. Это позволяет таким вещам, как перенаправление трафика и мигрирование тем по кластерам Kafka. Для приложений, не являющихся Java, они могут отправлять события в конечные точки REST Keystone, которые передают сообщения для фронталов кластеров Kafka.
Кафка внутри трубопровода Keystone
У нас есть два набора кластеров Kafka в трубопроводе Keystone:. Fronting Kafka кластеры несут ответственность за получение сообщений от производителей, которые практически каждый экземпляр приложения в Netflix. Их роли – сбор данных и буферизация для систем вниз по течению. Кластеры потребителей Кафки содержат подмножество тем, направленных Samza для потребителей в реальном времени.
В настоящее время мы управляем 36 кластерами Kafka, состоящими из более чем более 4000 экземпляров брокера как для выхода из Кафки, так и для потребителя Кафки. Более 700 миллиардов сообщений принимают в средний день. В настоящее время мы переходим из Kafka версии 0.8.2.От 1 до 0.9.0.1.
Принципы дизайна
Учитывая текущую архитектуру Kafka и наш огромный объем данных, для достижения без потерь доставки для нашего конвейера данных являются чрезмерными в AWS EC2. Учет этого, мы’В работал с командами, которые зависят от нашей инфраструктуры, чтобы получить приемлемый объем потери данных, при этом сбалансировать затраты. Мы’вел ежедневную скорость потери данных менее 0.01%. Метрики собираются для сброшенных сообщений, поэтому мы можем принять меры, если это необходимо.
Кейпновый трубопровод дает сообщения асинхронно, не блокируя приложения. В случае, если сообщение не может быть доставлено после повторных поисков, он будет отброшен производителем, чтобы обеспечить наличие приложения и хорошего пользовательского опыта. Вот почему мы выбрали следующую конфигурацию для нашего продюсера и брокера:
- Acks = 1
- блокировать.на.буфер.Полный = ложь
- нечистый.лидер.выборы.inable = true
Большинство приложений в Netflix используют нашу клиентскую библиотеку Java, чтобы произвести в Keystone Pipeline. В каждом экземпляре этих приложений существует несколько производителей кафки, каждый из которых производит в фронте кафки кластер для изоляции уровня раковины. Производители имеют гибкую маршрутизацию темы и конфигурацию погружения, которые обусловлены динамической конфигурацией, которую можно изменить во время выполнения без необходимости перезагрузки процесса применения. Это позволяет таким вещам, как перенаправление трафика и мигрирование тем по кластерам Kafka. Для приложений, не являющихся Java, они могут отправлять события в конечные точки REST Keystone, которые передают сообщения для фронталов кластеров Kafka.
Для большей гибкости производители не используют ключевые сообщения. Приблизительный заказ сообщений восстанавливается на уровне пакетной обработки (Hive / Elasticsearch) или уровне маршрутизации для потоковых потребителей.
Мы ставим стабильность наших фронтальных кластеров Kafka с высоким приоритетом, потому что они являются шлюзом для инъекции сообщений. Поэтому мы не позволяем клиентским приложениям напрямую потреблять из них, чтобы убедиться, что они имеют предсказуемую нагрузку.
Проблемы управления кафкой в облаке
Кафка была разработана с помощью центра обработки данных в качестве цели развертывания в LinkedIn. Мы приложили заметные усилия, чтобы заставить Кафку лучше работать в облаке.
В облаке экземпляры имеют непредсказуемый жизненный цикл и могут быть прекращены в любое время из-за проблем с оборудованием. Ожидаются проблемы с переходной сетью. Это не проблемы для без сохранения состояния, но представляют собой большую проблему для государственной службы, требующей зооукии и одного контроллера для координации.
Большинство наших проблем начинаются с выбросов брокеров. Выброс может быть вызван неравномерной рабочей нагрузкой, проблемами с оборудованием или его конкретной средой, например, шумных соседей из-за многоцелевого. Выбросный брокер может иметь медленные ответы на запросы или частые тайм -ауты TCP/ретрансмиссии. Производители, которые отправляют события такому брокеру. Другим фактором, способствующим истощению буфера, является то, что кафка 0.8.2 продюсер’T Поддержка тайм -аута для сообщений, ожидающих в буфере.
Кафка’S репликация улучшает доступность. Тем не менее, репликация приводит к взаимозависимости среди брокеров, где выброс может вызвать каскадный эффект. Если выброс замедляет репликацию, задержка репликации может нарастать и в конечном итоге заставит лидеров разделов читать с диска для обслуживания запросов на репликацию. Это замедляет пораженные брокеры и в конечном итоге приводит к тому, что производители отбрасывают сообщения из -за истощенного буфера, как объяснено в предыдущем случае.
В течение наших первых дней эксплуатации Kafka мы пережили инцидент, когда производители бросали значительное количество сообщений в кластер Kafka с сотнями случаев из -за проблемы с зоопером, в то время как мы мало что могли сделать. Такие проблемы отладки в маленьком временном окне с сотнями брокеров просто не реалистичны.
После инцидента были предприняты усилия по сокращению государственности и сложности для наших кластеров Кафки, обнаружения выбросов и найти способ быстро начать с чистого состояния, когда происходит инцидент.
Стратегия развертывания Кафки
Ниже приведены ключевые стратегии, которые мы использовали для развертывания кластеров Kafka
- Благоприятствуем нескольким небольшим кластерам кафки, а не к одному гигантскому кластеру. Это уменьшает рабочую сложность для каждого кластера. В нашем крупнейшем кластере менее 200 брокеров.
- Ограничьте количество разделов в каждом кластере. Каждый кластер имеет менее 10000 перегородков. Это улучшает доступность и уменьшает задержку для запросов/ответов, которые связаны с количеством разделов.
- Стремиться к ровному распределению реплик для каждой темы. Даже рабочая нагрузка легче для планирования и обнаружения выбросов.
- Используйте выделенный кластер Zookeeper для каждого кластера Kafka, чтобы уменьшить влияние проблем с зоочепом.
В следующей таблице показаны наши конфигурации развертывания.
Кафка отключение
Мы автоматизировали процесс, когда мы можем переключить как производителя, так и потребительский (маршрутизатор) трафик в новый кластер Kafka, когда в первичном кластере возникает проблема. Для каждого фронтального кластера Kafka существует холодный резервный кластер с желаемой конфигурацией запуска, но минимальная начальная емкость. Чтобы гарантировать чистое состояние для начала, в кластере отказа от аварийного покрытия не создано темы и не разделяет кластер Zookeeper с основным кластером Kafka. Столовая кластер также предназначен для того, чтобы иметь коэффициент репликации 1, чтобы он был свободен от любых проблем репликации, которые может иметь исходный кластер.
Когда происходит аварийное переключение, предпринимаются следующие шаги, чтобы отвлечь трафик производителя и потребителей:
- Изменить размер кластера отказа от желаемого размера.
- Создать темы и запустить задания по маршрутизации для абонезного кластера параллельно.
- (Необязательно) Подождите, чтобы лидеры раздела были установлены контроллером, чтобы минимизировать начальное падение сообщения при произведении к нему.
- Динамически изменить конфигурацию производителя на переключение трафика производителя на отказоустойчивый кластер.
Сценарий аварийного переключения может быть изображен следующей диаграммой:
При полной автоматизации процесса мы можем сделать отказоустойчивость менее чем за 5 минут. После того, как отказоустойчиво завершится успешно, мы можем отлаживать проблемы с исходным кластером, используя журналы и метрики. Также можно полностью уничтожить кластер и восстановить с помощью новых изображений, прежде чем мы переключим трафик. Фактически, мы часто используем стратегию отказа для перевода трафика при выполнении автономного обслуживания. Так мы обновляем наши кластеры Kafka до новой версии Kafka, не имея необходимости выполнять обновление или установить версию протокола связи между брокерами.
Развитие для Кафки
Мы разработали довольно много полезных инструментов для кафки. Вот некоторые из основных моментов:
Производитель липкий разместитель
Это специальный индивидуальный разместитель, который мы разработали для нашей библиотеки продюсеров Java. Как следует из названия, оно придерживается определенного раздела для создания на настраиваемое количество времени, прежде чем случайным образом выбирать следующее разделение. Мы обнаружили, что использование липкого разместителя вместе с затяжкой помогает улучшить количество сообщений и уменьшить нагрузку для брокера. Вот таблица, чтобы показать эффект липкого разместителя:
Назначение реплики с репликой на стойке
Все наши кластеры кафки охватывают в трех зонах доступности AWS. Зона доступности AWS – это концептуально стойка. Чтобы обеспечить доступность в случае, если одна зона выйдет из строя, мы разработали задание реплики, осведомленную о реплике, чтобы реплики для одной и той же темы были назначены в разные зоны. Это не только помогает снизить риск отключения зоны, но и улучшать нашу доступность, когда несколько брокеров совместно сражаются на одном и том же физическом хозяине, из-за проблем с хозяином. В этом случае у нас есть лучшая терпимость к ошибкам, чем Кафка’S n – 1, где n – коэффициент репликации.
Работа вносится в общину Kafka в KIP-36 и Apache Kafka GitHub запрос № 132 #132.
Кафка метаданный визуализатор
Кафка’S Метаданные хранятся в Zookeeper. Тем не менее, представление о дереве, предоставленное экспонентом.
Мы создали свой собственный пользовательский интерфейс для визуализации метаданных. Он предоставляет как диаграммы, так и табличные виды и использует богатые цветовые схемы для обозначения состояния ISR. Ключевые функции следующие:
- Индивидуальная вкладка для представлений для брокеров, тем и кластеров
- Большая часть информации сортируется и доступна для поиска
- Поиск тем по кластерам
- Прямое отображение от идентификатора брокера на идентификатор экземпляра AWS
- Корреляция брокеров по отношениям лидера
Ниже приведены скриншоты пользовательского интерфейса:
Мониторинг
Мы создали специальную службу мониторинга для Кафки. Это отвечает за отслеживание:
- Статус брокера (в частности, если он не в автономном режиме от Zookeeper)
- Маклер’Способность получать сообщения от производителей и доставлять сообщения потребителям. Служба мониторинга выступает как производитель, так и потребитель для непрерывных сообщений о сердцебиениях и измеряет задержку этих сообщений.
- Для потребителей на основе старых зооукеров это отслеживает количество разделов для группы потребителей, чтобы убедиться, что каждый раздел потребляется.
- Для маршрутизаторов Keystone Samza он отслеживает клеточные смещения и сравнивается с брокером’S Входные смещения, чтобы убедиться, что они не застряли и не имеют существенного задержки.
Кроме того, у нас есть обширные панели мониторинга для мониторинга потока трафика до уровня темы и большинства брокеров’S Метрики.
Будущий план
В настоящее время мы находимся в процессе перехода на Кафку 0.9, в котором есть немало функций, которые мы хотим использовать, включая новые API -интерфейсы потребителей, тайм -аут сообщения производителя и квоты. Мы также перенесем наши кластеры Kafka в AWS VPC и полагаем, что его улучшение сети (по сравнению с EC2 Classic) даст нам преимущество для улучшения доступности и использования ресурсов.
Мы собираемся представить многоуровневую SLA по темам. Что касается тем, которые могут принять незначительные потери, мы рассматриваем использование одной копии. Без репликации мы не только сохраняем огромную пропускную способность, но и минимизируем изменения состояния, которые должны зависеть от контроллера. Это еще один шаг, чтобы сделать Кафку менее государственной в среде, которая поддерживает услуги без сохранения состояния. Недостатком является потенциальная потеря сообщения, когда брокер уходит. Однако, используя тайм -аут сообщения продюсера в 0.9 выпустить и, возможно, объем AWS EBS, мы можем смягчить потерю.
Оставайтесь с нами для будущих блогов Keystone на нашей инфраструктуре маршрутизации, управлении контейнерами, обработкой потоков и многое другое!
Показ Апач Кафка в Netflix Studio и Finance World
Netflix потратил около 15 миллиардов долларов на производство оригинального контента мирового класса в 2019 году. Когда ставки настолько высоки, важно позволить нашему бизнесу с критическими идеями, которые помогают планировать, определять расходы и учитывать все контент Netflix. Эти идеи могут включать в себя:
- Сколько мы должны провести в следующем году на международные фильмы и сериалы?
- Мы в тенденции преодолеть наш производственный бюджет и нужно ли кому -нибудь вмешаться, чтобы сохранить вещи на пути?
- Как мы можем запрограммировать каталог за годы с данными, интуицией и аналитикой, чтобы помочь создать наилучший выбор?
- Как мы производим финансовые показатели для контента по всему миру и сообщить на Уолл -стрит?
Подобно тому, как VCS строго настраивает свое внимание на хорошие инвестиции, команда инженерии по финансированию контента’S Charter заключается в том, чтобы помочь Netflix инвестировать, отслеживать и учиться на наших действиях, чтобы мы постоянно делали лучшие инвестиции в будущем.
Принять события
С технической точки зрения каждое финансовое приложение смоделировано и реализуется как микросервис. Netflix использует распределенное управление и поощряет подход, основанный на микросервисах к приложениям, который помогает достичь правильного баланса между абстракцией данных и скоростью, поскольку компания масштабирует. В простом мире услуги могут взаимодействовать с помощью HTTP просто хорошо, но по мере того, как мы масштабируем, они превращаются в сложный график синхронных, основанных на запросах взаимодействий, которые потенциально могут привести к расщепленному мозгу/состоянию и нарушают доступность.
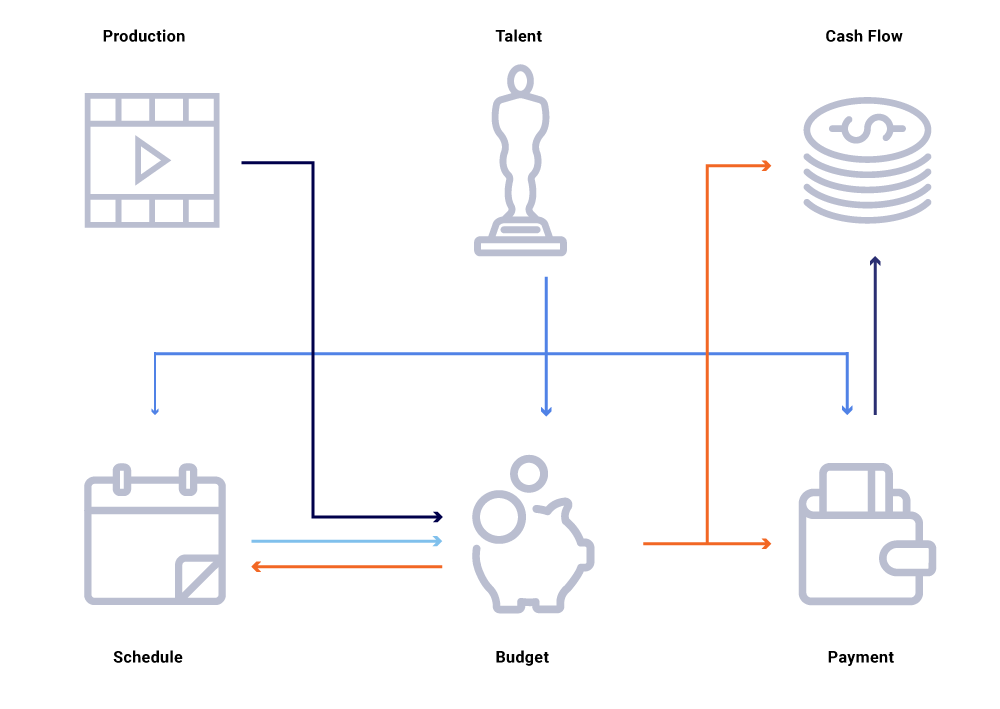
Рассмотрим на приведенном выше графике связанных объектов изменение даты производства шоу. Это влияет на наш план программирования, который, в свою очередь, влияет на проекты денежных потоков, выплаты талантов, бюджеты на год и т. Д. Часто в архитектуре микросервиса некоторый процент отказа приемлем. Тем не менее, сбой в любом из микросервисных призывов для инженерии по финансированию контента приведет к тому, что множество вычислений не синхронизируются и могут привести к выключению данных на миллионы долларов. Это также приведет к проблемам с доступностью, поскольку график вызовов простирается и вызывает слепые пятна, пытаясь эффективно отслеживать и ответить на вопросы по бизнесу, например: почему прогнозы денежных потоков отклоняются от нашего графика запуска? Почему прогноз на текущий год не учитывает шоу, которые находятся в активной разработке? Когда мы сможем ожидать, что наши отчеты о затратах будут точно отражать изменения вверх по течению?
Переосмысление взаимодействия услуг как потоки обменов событиями – в отличие от последовательности синхронных запросов – позволяет США построить инфраструктуру, которая по своей природе асинхронна. Он способствует развязке и обеспечивает прослеживаемость как первоклассный гражданин в сети распределенных транзакций. События гораздо больше, чем триггеры и обновления. Они становятся неизменным потоком, из которого мы можем реконструировать все состояние системы.
Переход к модели публикации/подписки позволяет каждому сервису публиковать свои изменения в качестве событий в автобус, который затем может быть использован другой интересной службой, которая необходимо скорректировать его состояние мира. Такая модель позволяет нам отслеживать, синхронизируются ли услуги в отношении изменений состояния и, если нет, как долго, прежде чем они могут быть синхронизированы. Эти идеи чрезвычайно мощные при работе с большим графом зависимых услуг. Общение на основе событий и децентрализованное потребление помогает нам преодолеть проблемы, которые мы обычно видим на больших графах синхронных вызовов (как упоминалось выше).
Netflix охватывает Apache Kafka ® в качестве стандарта de-facto для его потребностей в сообщениях, обменах и обработке потоков. Кафка действует как мост для всех коммуникаций с точки зрения и Netflix Studio. Он предоставляет нам высокую долговечность и линейно масштабируемую, мультитенантную архитектуру, необходимую для операционных систем в Netflix. Наша внутренняя кафка в качестве услуги обеспечивает устойчивость к неисправности, наблюдение, мультирегионные развертывания и самообслуживание. Это облегчает для всей нашей экосистемы микросервисов легко производить и потреблять значимые события и развязать силу асинхронной связи.
Типичный обмен сообщениями в Netflix Studio Ecosystem выглядит так:
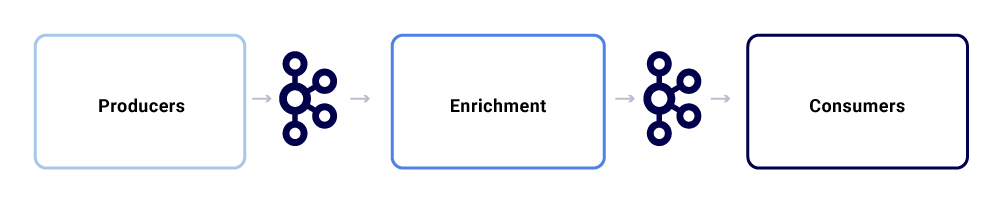
Мы можем разбить их как три основных субкомпонента.
Производители
Производитель может быть любой системой, которая хочет опубликовать все свое состояние или намекнуть на то, что критическая часть его внутреннего состояния изменилась для конкретной организации. Помимо полезной нагрузки, событие должно придерживаться нормализованного формата, что облегчает отслеживание и понимание. Этот формат включает в себя:
- Uuid: Универсально уникальный идентификатор
- Тип: Один из типов создания, чтения, обновления или удаления (CRUD)
- TS: Временная метка мероприятия
Инструменты сбора данных изменения данных (CDC) являются еще одной категорией производителей событий, которые выводят события из изменений базы данных. Это может быть полезно, если вы хотите сделать изменения в базе данных, доступных для нескольких потребителей. Мы также используем этот шаблон для воспроизведения одних и тех же данных по сравнению с обратными центрами (для отдельных основных баз данных). Примером является то, когда у нас есть данные в MySQL, которые необходимо индексировать в Elasticsearch или Apache Solr ™. Преимущество использования CDC заключается в том, что он не налагает дополнительную нагрузку на исходное приложение.
Для событий CDC поле типа в формате событий позволяет легко адаптировать и преобразовать события, как требуется соответствующие раковины.
Обогатители
Как только данные существуют в Кафке, к нему могут применяться различные модели потребления. События используются во многих отношениях, в том числе в качестве триггеров для системных вычислений, передача полезной нагрузки для связи почти в реальном времени и сигналы для обогащения и материализации представлений в памяти данных.
Обогащение данных становится все более распространенным, когда микросервисы нуждаются в полном представлении набора данных, но часть данных поступает из другой службы’S набор данных. Соединенный набор данных может быть полезен для улучшения производительности запроса или обеспечения почти в реальном времени представление об агрегированных данных. Чтобы обогатить данные о событиях, потребители читают данные из KAFKA и вызывают другие службы (использующие методы, которые включают GRPC и GRAPHQL) для построения соединенного набора данных, которые затем подаются в другие темы KAFKA.
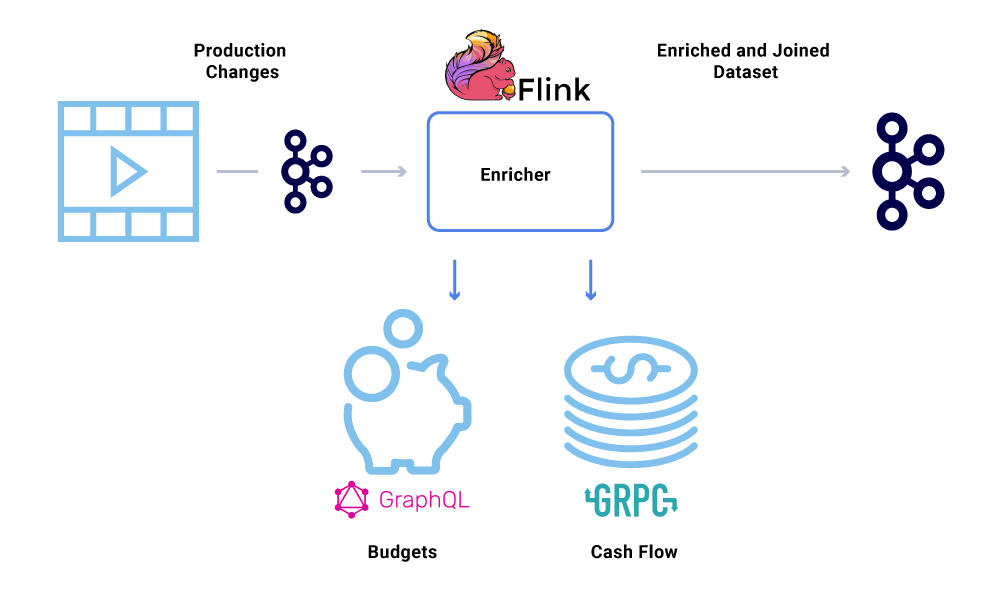
Обогащение может быть запущено в качестве отдельного микросервиса, которое отвечает за разграбление и за материализование наборов данных. Есть случаи, когда мы хотим сделать более сложную обработку, например, окно, сеанс и управление государством. Для таких случаев рекомендуется использовать двигатель для обработки зрелого потока на вершине Kafka для создания бизнес -логики. В Netflix мы используем Apache Flink ® и RocksDB для выполнения обработки потока. Мы’Re также рассматривать KSQLDB для аналогичных целей.
Заказ событий
Одним из ключевых требований в рамках финансового набора данных является строгий заказ событий. Кафка помогает нам достичь этого, отправляя ключевые сообщения. Любое событие или сообщение, отправленное с одним и тем же ключом, будет иметь гарантированное заказ, так как они отправляются в тот же раздел. Тем не менее, производители все еще могут испортить заказ событий.
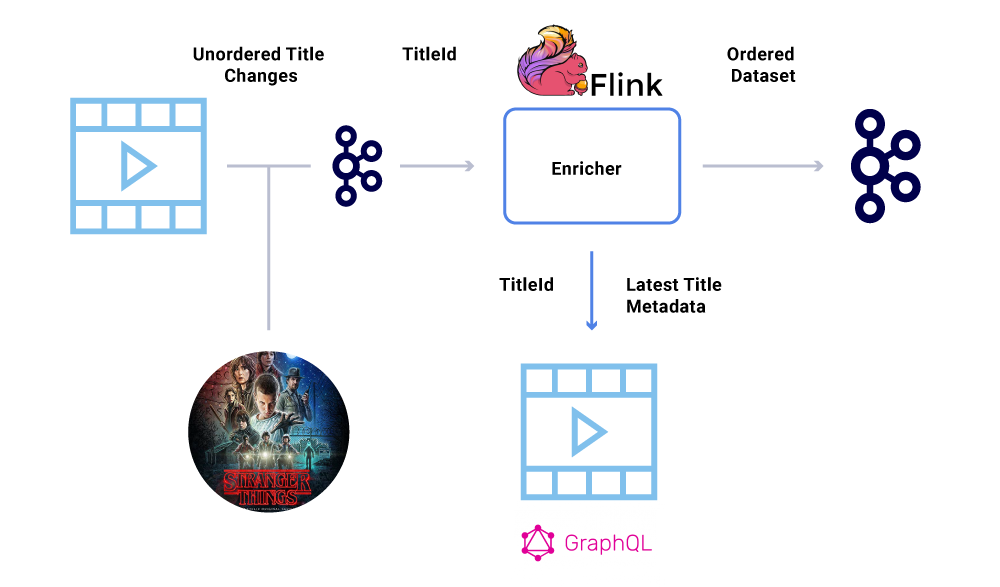
Например, дата запуска “Незнакомец” Первоначально был перенесен с июля по июнь, но затем с июня по июль. По разным причинам эти события могут быть написаны в неправильном порядке в Кафку (сетевой тайм -аут, когда продюсер попытался связаться с кафкой, ошибкой параллелизма в коде производителя и т. Д.). Иккинг на заказ мог бы сильно повлиять на различные финансовые расчеты.
Чтобы обойти этот сценарий, продюсерам рекомендуется отправить только основной идентификатор объекта, которая изменилась, а не полная полезная нагрузка в сообщении Kafka. Процесс обогащения (описанный в вышеупомянутом разделе) Запросы запрашивают исходную службу с идентификатором объекта, чтобы получить наиболее современное состояние/полезную нагрузку, что обеспечивает элегантный способ обойти проблему вне заказа. Мы называем это как Задержка материализации, и это гарантирует упорядоченные наборы данных.
Потребители
Мы используем Spring Boot для реализации многих потребляющих микросервисов, которые читаются по темам Кафки. Spring Boot предлагает отличные встроенные потребители Kafka под названием Spring Kafka Connectors, которые делают потребление бесшовным, обеспечивая простые способы подключения аннотаций для потребления и десериализации данных.
Один аспект данных, которые мы доявим’T обсуждали еще контракты. Поскольку мы масштабируем наше использование потоков событий, мы получим разнообразную группу наборов данных, некоторые из которых потребляются большим количеством приложений. В этих случаях определение схемы на выходе идеально и помогает обеспечить обратную совместимость. Для этого мы используем реестр схемы схемы и Apache Avro ™ для создания наших схематизированных потоков для потоков данных версий.
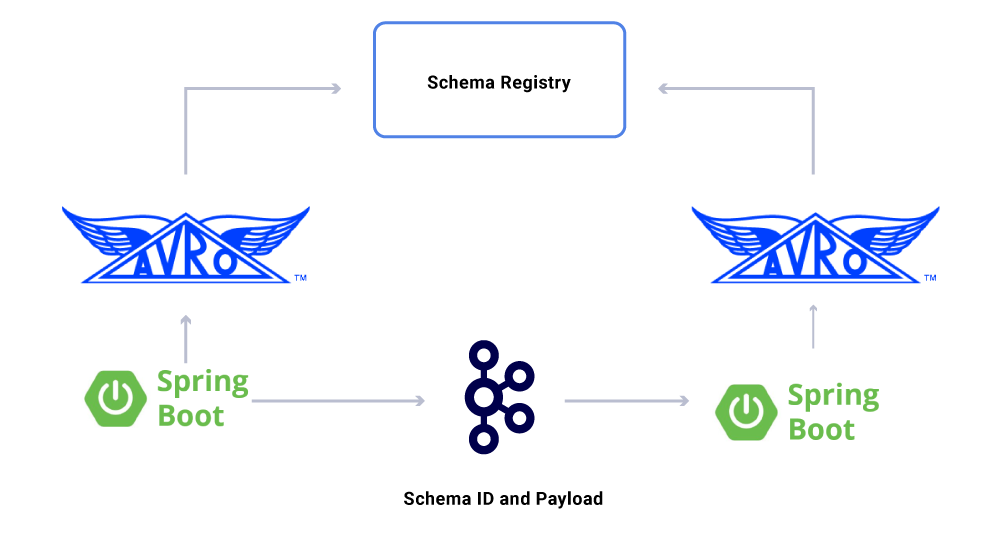
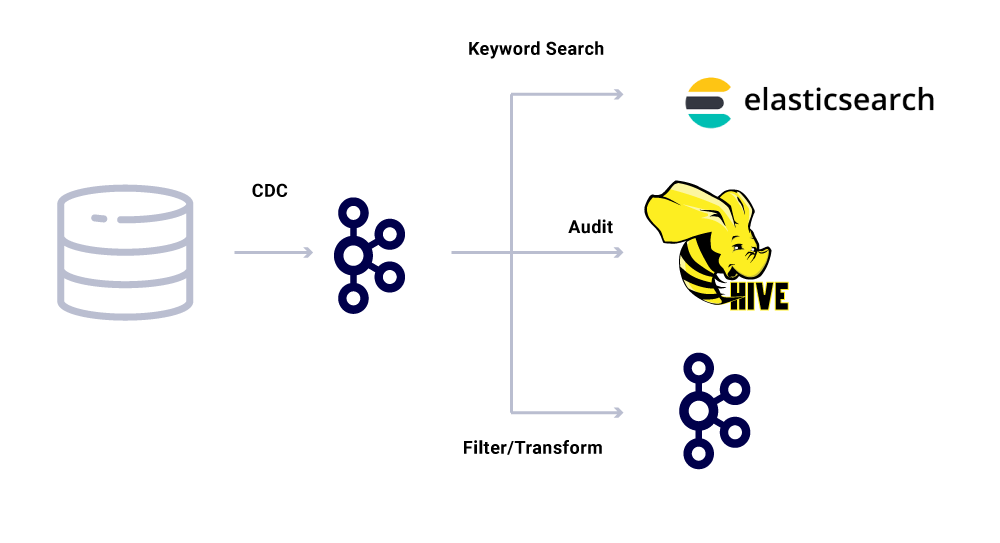
В дополнение к специализированным потребителям микросервиса, у нас также есть раковины CDC, которые индексируют данные в различные запасы для дальнейшего анализа. К ним относятся Elasticsearch для поиска ключевых слов, Apache Hive ™ для аудита и самого Kafka для дальнейшей обработки вниз по течению. Полезная нагрузка для таких раковин непосредственно получена из сообщения Kafka с использованием поля ID в качестве первичного ключа и типа для идентификации операций CRUD.
Гарантии доставки сообщений
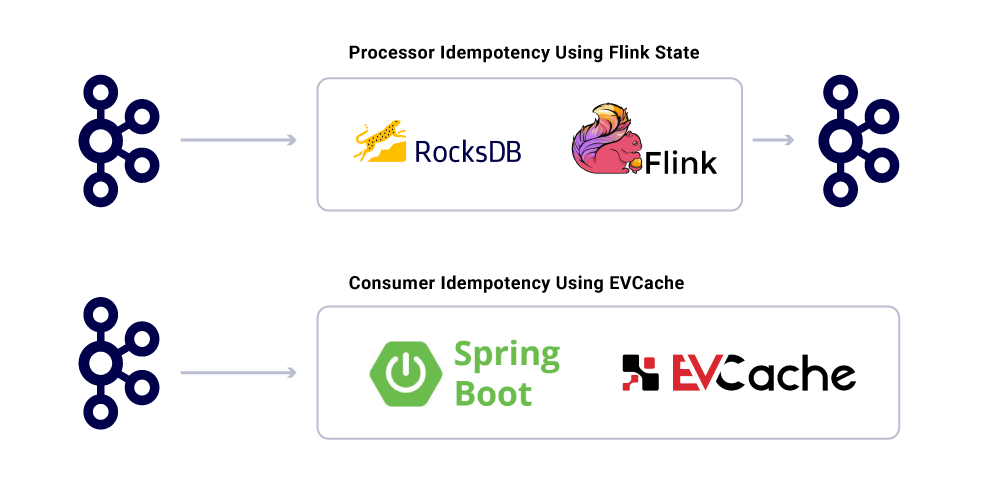
Гарантирование точно, когда доставка в распределенной системе не являетсятривиальной из -за сложностей и множества движущихся частей. Потребители должны иметь идентификационное поведение, чтобы учесть любую потенциальную инфраструктуру и неудачи производителей.
Несмотря на то, что приложения идентифицируются, они не должны повторять вычислительные операции для уже обработанных сообщений. Популярный способ обеспечить отслеживание UUID сообщений, потребляемых сервисом в распределенном кэше с разумным истечением (определяется на основе соглашений об уровне обслуживания (SLA). В любое время, когда тот же UUID встречается в интервале истечения, обработка пропускается.
Обработка в Flink обеспечивает эту гарантию, используя его внутреннее управление государством на основе RockSDB, причем ключом является UUID сообщения. Если вы хотите сделать это исключительно, используя Kafka, Kafka Streams предлагает способ сделать это тоже. Потребление приложений на основе использования Spring Boot Evcache для достижения этого.
Мониторинг уровней обслуживания инфраструктуры
Это’S Netflix имеет представление о уровнях обслуживания в рамках своей инфраструктуры. Netflix писал Atlas для управления данными размерных временных рядов, из которых мы публикуем и визуализируем метрики. Мы используем различные показатели, опубликованные производителями, процессорами и потребителями, чтобы помочь нам построить почти в реальную картину всей инфраструктуры.
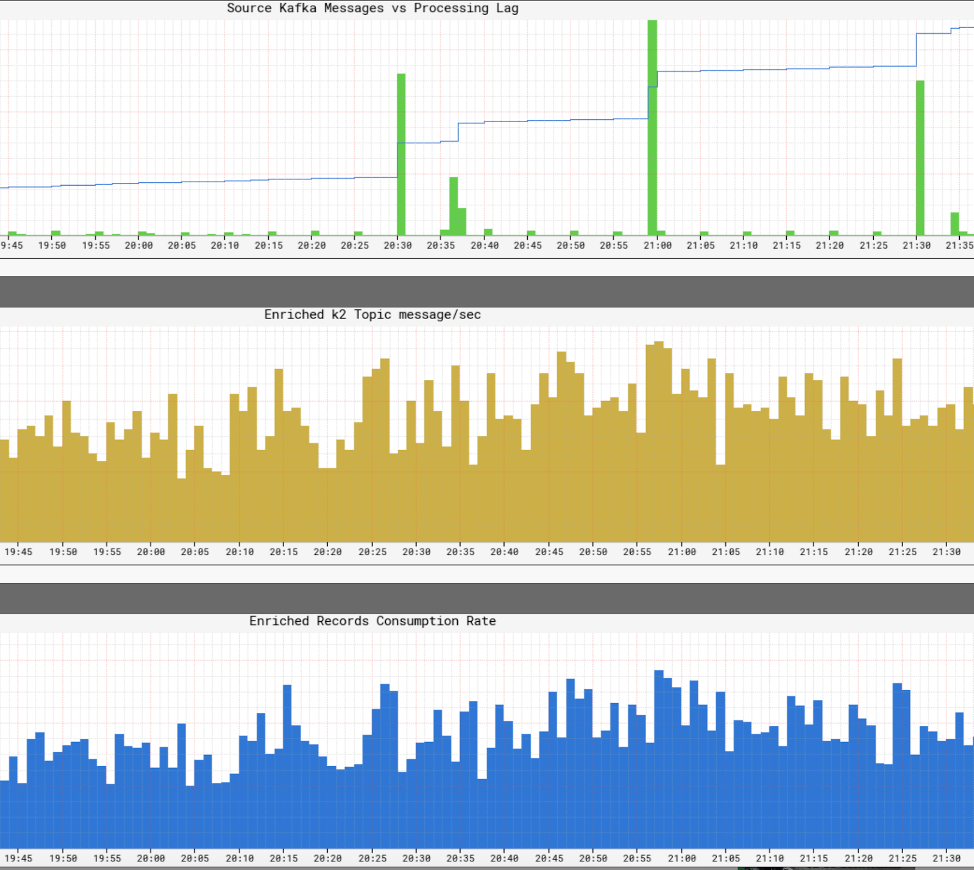
Некоторые из ключевых аспектов, которые мы наблюдаем, являются:
- Свежесть Sla
- Какое время заканчивается до конца от производства события, пока оно не достигнет всех раковин?
- Что такое задержка обработки для каждого потребителя?
- Насколько велика полезная нагрузка мы можем отправить?
- Должны ли мы сжать данные?
- Мы эффективно используем наши ресурсы?
- Можем ли мы потреблять быстрее?
- Мы можем создать контрольно -пропускной пункт для нашего состояния и возобновить в случае сбоев?
- Если мы не можем идти в ногу с пожарным управлением, можем ли мы применить обратное давление на соответствующие источники, не сбивая нашу заявку?
- Как мы справляемся с всплесками событий?
- Достаточно ли мы подготовлены, чтобы встретить SLA?
Синопсис
Netflix Studio Productions and Finance Team использует распределенное управление как путь архитекции систем. Мы используем Kafka в качестве нашей платформы для работы с событиями, которые являются неизменным способом записи и получения состояния системы. Кафка помогла нам достичь более высокого уровня видимости и развязки в нашей инфраструктуре, помогая нам органически масштабировать операции. Он лежит в основе революционной инфраструктуры Netflix Studio, а также в киноиндустрии.
Заинтересован в большем?
Если вы’D Хотел бы узнать больше, вы можете просмотреть запись и слайды моего саммита Кафки Сан -Франциско события – оригинал Netflix!
Netflix: как Apache Kafka превращает данные из миллионов в интеллект
Netflix потратил 16 миллиардов долларов на производство контента в 2020 году. В январе 2021 года мобильное приложение Netflix (iOS и Android) было загружено 19 миллионов раз, а через месяц компания объявила, что достигла 203.66 миллионов подписчиков по всему миру. Это’S, с уверенностью предположить, что масштаб данных, которые компания собирает и процессы, является массивным. Вопрос в том –
Как Netflix обрабатывает миллиарды записей и событий данных для принятия важных бизнес -решений?
С годовым бюджетом контента на сумму 16 миллиардов долларов, принимающие решения в Netflix Aren’T собираюсь принимать решения, связанные с контентом на основе интуиции. Вместо этого их кураторы контента используют передовые технологии для размывания огромных объемов данных о поведении абонента, предпочтениях пользовательского контента, затратах на производство контента, типах контента, которые работают и т. Д. Этот список продолжается.
Пользователи Netflix тратят в среднем 3.2 часа в день на своей платформе и постоянно питаются последними рекомендациями Netflix’Собственная Рекомендационный двигатель. Это гарантирует, что отток подписчиков является низким и побуждает новых подписчиков зарегистрироваться. Доставка контента, управляемого данными, находится на передней части и в центре этого.
Итак, что лежит под капотом с точки зрения обработки данных?
Другими словами, как Netflix построил технологическую основу, которая позволила принять решения, управляемые данными в таком масштабе, в таком масштабе? Как разобраться в поведении пользователя в 203 миллиона подписчиков?
Netflix использует то, что он называет трубопровод данных Keystone. В 2016 году этот трубопровод обрабатывал 500 миллиардов мероприятий в день. Эти события включали в себя журналы ошибок, мероприятия по просмотру пользователей, действия пользовательского интерфейса, устранение неполадок и многие другие ценные наборы данных.
Согласно Netflix, как опубликовано в его техническом блоге:
Кейстоун -конвейер – это единая инфраструктура публикации, сбора и маршрутизации Unified Publishing и маршрутизации.
Кафка кластеры являются основной частью конвейера данных Keystone в Netflix. В 2016 году трубопровод Netflix использовал 36 кластеров Kafka для обработки миллиардов сообщений в день.
Итак, что такое Apache Kafka? И почему это стало таким популярным?
Apache Kafka-это потоковая платформа с открытым исходным кодом, которая позволяет разработать приложения, которые принимают большой объем данных в реальном времени. Первоначально он был построен гениями в LinkedIn и теперь используется в Netflix, Pinterest и Airbnb, чтобы назвать несколько.
Кафка специально делает четыре вещи:
- Это позволяет приложениям публиковать или подписаться на потоки данных или событий
- Он хранит записи данных точно и сильно устойчив к
- Он способен к обработке данных в режиме реального времени.
- Он может принимать и обрабатывать триллионы записей данных в день без каких -либо проблем с производительностью
Команды разработки программного обеспечения могут использовать kafka’S возможностей со следующими API:
- API -производитель: этот API позволяет микросервиса или приложения публиковать поток данных в конкретную тему Kafka. Тема Kafka – это журнал, который хранит данные и записи событий в том порядке, в котором они произошли.
- Потребительский API: этот API позволяет приложению подписаться на потоки данных из темы Kafka. Используя API потребителя, приложения могут приглашать и обрабатывать поток данных, который будет служить входным введением в указанное приложение.
- API Streams: Этот API имеет решающее значение для сложных приложений потокового вещества и потоковых событий. По сути, он потребляет потоки данных из различных тем Kafka и способен обрабатывать или преобразовать это по мере необходимости. Пост-обработка, этот поток данных опубликован в другую тему Kafka, которая будет использоваться вниз по течению и/или преобразовать существующую тему.
- API Connector: в современных приложениях существует постоянная необходимость повторного использования производителей или потребителей и автоматически интегрировать источник данных в кластер Kafka. Kafka Connect делает это ненужным по подключению kafka к внешним системам.
Ключевые преимущества кафки
Согласно веб -сайту Kafka, 80% всех компаний Fortune 100 используют Kafka. Одна из главных причин этого заключается в том, что он хорошо вписывается в критически важные приложения.
Крупные компании используют Kafka по следующим причинам:
- Это позволяет легко разместить потоки и системы данных
- Он предназначен для распределения, устойчивого и устойчивого к устойчивости
- Горизонтальная масштабируемость Кафки является одним из самых больших преимуществ. Он может масштабироваться до 100 кластеров и миллионов сообщений в секунду
- Он обеспечивает высокоэффективную потоковую передачу данных в реальном времени, что является критической потребностью в крупномасштабных приложениях, управляемых данными
Способы использования кафки для оптимизации обработки данных
Кафка используется в разных отраслях для различных целей, включая, помимо прочего, не ограничиваясь следующими
- Обработка данных в реальном времени: В дополнение к его использованию в технологических компаниях, Kafka является неотъемлемой частью обработки данных в реальном времени в производственной отрасли, где данные высокого объема поступают из большого количества устройств IoT и датчиков
- Мониторинг веб -сайта в масштабе: Кафка используется для отслеживания поведения пользователей и активности сайта на веб-сайтах с высоким трафиком. Это помогает с мониторингом в реальном времени, обработке, подключении к Hadoop и офлайн-хранилищам данных
- Отслеживание ключевых метрик: Поскольку KAFKA можно использовать для агрегирования данных из разных приложений в централизованный корм, это облегчает мониторинг операционных данных высокого объема
- Агрегация журнала: Это позволяет агрегировать данные из нескольких источников в журнал, чтобы получить ясность при распределенном потреблении
- Система обмена сообщениями: Он автоматизирует крупномасштабные приложения обработки сообщений
- Обработка потоков: После того, как темы Kafka используются в качестве необработанных данных при обработке трубопроводов на разных этапах, он агрегируется, обогащена или иным образом преобразуется в новые темы для дальнейшего потребления или обработки
- Зависимости системы Decoupling
- Интеграции С Spark, Flink, Storm, Hadoop и другими технологиями больших данных
Компании, которые используют Kafka для обработки данных
В результате его универсальности и функциональности Кафка используется некоторыми из мира’S наиболее быстро растущие технологические компании для различных целей:
- Uber-Соберите данные пользователя, такси и поездки в режиме реального времени для вычисления и прогнозирования спроса и вычисления цен в режиме реального времени в режиме реального времени
- LinkedIn-предотвращает спам и собирает взаимодействие с пользователями, чтобы сделать более эффективные рекомендации по соединению в режиме реального времени
- Twitter – часть его инфраструктуры обработки штормового потока
- Spotify – часть системы доставки журналов
- Pinterest – часть своего конвейера сбора журналов
- Airbnb – Трубопровод событий, отслеживание исключений и т. Д.
- Cisco – для OpenSoc (Центр операций безопасности)
Заслуга Группа’S Experize в Кафке
В группе заслуги мы работаем с некоторыми из мира’S ведущие разведывательные компании B2B, такие как Уилмингтон, Доу Джонс, Глениган и Хеймаркет. Наши команды данных и инженеров тесно сотрудничают с нашими клиентами для создания продуктов для данных и инструментов бизнес -аналитики. Наша работа напрямую влияет на рост бизнеса, помогая нашим клиентам выявлять возможности высокого роста.
Наши конкретные услуги включают в себя сбор данных больших объемов, преобразование данных с использованием AI и ML, просмотра веб-страниц и разработки индивидуальных приложений.
Наша команда также привносит в таблицу глубокие экспертизы в создании приложений и обработки данных в режиме реального времени и обработки данных. Наш опыт в Кафке особенно полезен в этом контексте.
PUBLYKAHINYUYURYAVNICA CONPLUENT
Для архитектуры систем, которые записывают и получают состояние системы, Netflix использует Apache Kafka и распределенное управление. Нитин с. Совместно, как это помогает им достичь видимости и развязки в своей инфраструктуре при органическом масштабировании операций: https: // lnkd.в/gfxaa6g
Как Netflix использует Kafka для распределенной потоковой передачи
слияние.io
- Копирово
Верующий, муж, отец 5, менеджер по инфраструктуре и услугам, руководитель группы, разработчик.
Netflix создает надежную, масштабируемую платформу с поиском событий, MQTT и Alpakka-Kafka
Netflix недавно опубликовал сообщение в блоге, в котором подробно рассказывается о том, как он создал надежную платформу управления устройствами, используя реализацию Sourcing на основе MQTT на основе MQTT. Чтобы масштабировать свое решение, Netflix использует Apache Kafka, Alpakka-Kafka и Tackroachdb.
Платформа управления устройствами Netflix – это система, которая управляет аппаратными устройствами, используемыми для автоматического тестирования его приложений. Инженеры Netflix Benson Ma и Alok Ahuja описывают путешествие, через которое прошла платформа:
Обработка потоков кафки может быть трудно получить правильно. (. ) К счастью, примитивы, предоставленные Akka Streams и Alpakka-Kafka, позволяют нам достичь именно этого, позволяя нам создавать потоковые решения, которые соответствуют бизнес-процессам, которые у нас есть, одновременно увеличивая производительность разработчика в создании и поддержании этих решений. С процессором на базе Alpakka-Kafka на месте (. ), мы обеспечили устойчивость к неисправности в потребительской стороне плоскости управления, что является ключом к тому, чтобы обеспечить точную и надежную агрегацию состояния устройства в платформе управления устройствами.
(. ) Надежность платформы и ее плоскости управления опирается на значительную работу, выполненную в нескольких областях, включая транспорт MQTT, аутентификацию и авторизация, а также мониторинг систем. (. ) В результате этой работы мы можем ожидать, что платформа управления устройствами продолжит масштабировать до увеличения рабочих нагрузок с течением времени, поскольку мы на борту все больше устройств в наши системы.
На следующей диаграмме изображена архитектура.

Источник: https: // netflixtechblog.com/ae-a-lemable-device-management-platform-4f86230ca623
Встроенный компьютер локальной среды автоматизации (RAE) подключается к нескольким тестовым устройствам (DUT). Служба локального реестра отвечает за обнаружение, адаптирование и поддержание информации обо всех подключенных устройствах на RAE. По мере того, как атрибуты и свойства устройства меняются с течением времени, это экономит эти изменения в локальном реестре и одновременно опубликовано вверх по течению в облачную плоскость управления. В дополнение к изменениям атрибутов, локальный реестр публикует полный снимок записи устройства через регулярные промежутки времени. Эти события контрольной точки обеспечивают более быструю реконструкцию состояния потребителями подачи данных, защищая от пропущенных обновлений.
Обновления публикуются в облаке с использованием MQTT. MQTT – это стандартный протокол обмена сообщениями OASIS для Интернета вещей (IoT). Это легкий, но надежный публикация/подписка на обмен сообщениями, идеально подходящий для подключения удаленных устройств с небольшим количеством кода и минимальной пропускной способности сети. Брокер MQTT отвечает за получение всех сообщений, фильтрации их и отправки их подписанным клиентам соответственно.
Netflix использует Apache Kafka на протяжении всей организации. Следовательно, мост преобразует сообщения MQTT в записи Kafka. Он устанавливает клавишу записи на тему MQTT, что сообщение было назначено. MA и Ahuja описывают, что «поскольку обновления устройств, опубликованные на MQTT device_session_id В этой теме все обновления информации о устройстве для данного сеанса устройства будут эффективно отображаться в одном и том же разделе Kafka, что дает нам четко определенный заказ сообщения для потребления.”
Облачный реестр принимает опубликованные сообщения, обрабатывает их и выдвигает материализованные данные в хранилище данных, поддерживаемое Tackroachdb. Tackroachdb – это реализация класса систем RDBMS под названием Newsql. Ма и Ахаджа объясняют выбор Netflix:
Tackroachdb выбирается в качестве хранилища данных, поскольку он предлагал возможности SQL, а наша модель данных для записей устройства была нормализована. Кроме того, в отличие от других магазинов SQL, TackRoachDB разработан с того, что он является горизонтально масштабируемым, что касается наших опасений по поводу способности облачных реестра масштабироваться с количеством устройств, на борту, на платформу управления устройствами.
На следующей диаграмме показан конвейер обработки кафки, включающий облачный реестр.

Источник: https: // netflixtechblog.com/ae-a-lemable-device-management-platform-4f86230ca623
Netflix рассмотрел много фреймворков для реализации конвейеров обработки потоков, изображенных выше. Эти рамки включают потоки кафки, Spring Kafkalistener, Project Reactor и Flink. В конечном итоге он выбрал альпакка-кафку. Причина этого выбора заключается в том, что Alpakka-Kafka обеспечивает интеграцию Spring Boot вместе с «мелкозернистым контролем над обработкой потока, включая автоматическую поддержку обратного давления и контроль потоков.”Кроме того, по словам Ма и Ахаджа, Акки и Альпакка-Кафки более легкие, чем альтернативы, и, поскольку они более зрелые, затраты на техническое обслуживание с течением времени будут ниже.
Реализация на основе Альпакка-Кафки заменила более раннюю весеннюю реализацию на основе Kafkalistsener. Метрики, измеренные на новой реализации производства, показывают, что поддержка нативной спины Альпакки-Кафки может динамически масштабировать потребление кафки. В отличие от Kafkalistener, Alpakka-Kafka не недооценивает или не является чрезмерным сообщением Kafka. Кроме того, падение максимальных значений задержки потребителей после выпуска показало, что Alpakka-Kafka и потоковые возможности Akka хорошо работают в масштабе, даже перед лицом внезапных нагрузок сообщений.