Собственный Google Datacenter
Краткое содержание:
– Google создает собственное сетевое оборудование и программное обеспечение для сети обработки данных.
– Их нынешнее поколение, Jupiter Fabrics, может обеспечить более 1 Petabit/Sec общей пропускной способности распределения пополам.
– Google использует топологию Clos, централизованный стек управления программным обеспечением и пользовательские протоколы для разработки своих сетей обработки данных обработки данных.
– Они развернули и пользуются преимуществами программного обеспечения, определенного сети (SDN) в течение десятилетия.
– Сети обработки данных Google созданы для скорости, модульности и доступности и являются общей инфраструктурой.
– Andromeda – это новейший сетевый стек Google Cloud Platform, основанный на программном обеспечении, определенном сети (SDN).
– Google строит новый центр обработки данных в Небраске в рамках своей 9 долларов.5 миллиардов инвестиций в центры обработки данных и офисов.
Уникальные вопросы:
1. Как Google создает свою сетевую инфраструктуру обработки данных обработки данных?
Google создает собственное сетевое оборудование и программное обеспечение для соединения всех серверов в своих обработках обработки данных, питание их распределенных вычислительных систем и хранения систем. Они делали это в течение последнего десятилетия.
2. Какова способность текущей сети обработки обработки данных Google?
Текущее поколение, называемое ткани Jupiter, может обеспечить более 1 Petabit/Sec общей пропускной способности распределения пополам. Эту емкость достаточно, чтобы 100 000 серверов обменивались информацией по 10 ГБ/с каждый.
3. Как Google разрабатывает свои сети обработки данных обработки данных?
Google использует топологию Clos, которая включает в себя расположение своей сети вокруг коллекции небольших коммутаторов, чтобы обеспечить свойства гораздо большего логического коммутатора. Они также используют централизованный стек управления программным обеспечением для управления тысячами коммутаторов в центре обработки данных, что заставляет их действовать как одна большая ткань. Кроме того, они создают свое собственное программное и аппаратное обеспечение, используя пользовательские протоколы, адаптированные к центру обработки данных.
4. Как долго Google развертывает и пользуется преимуществами программного обеспечения, определенного сети (SDN)?
Google развертывает и наслаждается преимуществами SDN в течение десятилетия. Они использовали SDN для питания своего DataCenter WAN, B4 и стека виртуализации сети SDN, Andromeda.
5. Каковы ключевые функции сети обработки данных Google?
Сети обработки данных Google обеспечивают беспрецедентную скорость, модульность и доступность. Они постоянно обновляются, чтобы удовлетворить требования пропускной способности своих последних поколений серверов. Эти сети также являются общими инфраструктурой, питание как внутренняя инфраструктура, так и услуги Google, а также платформу Google Cloud.
6. Что такое Andromeda и как это связано с платформой Google Cloud?
Andromeda-это программное обеспечение, определенное сетью (SDN) субстрат для усилий по виртуализации сети Google. Это точка оркестровки для обеспечения, настройки и управления виртуальными сетями и обработкой пакетов в сети на платформе Google Cloud Platform.
7. Каков инвестиционный план Google для центров обработки данных и офисов?
.5 миллиардов в центрах обработки данных и офисов, и в рамках этого плана они строят новый центр обработки данных в штате Небраска.
8. Почему Google создает собственное сетевое оборудование и программное обеспечение для сети обработки данных?
Google начал создавать собственное сетевое оборудование и программное обеспечение, потому что не было никаких существующих решений, которые могли бы соответствовать их распределенным вычислительным требованиям. Они продолжали делать это, чтобы обеспечить отличную вычислительную инфраструктуру для своих центров обработки данных.
9. Каковы принципы, используемые Google при разработке своих сетей обработки данных обработки данных?
Google использовал три ключевых принципа при разработке своих сетей обработки данных: расположение сети вокруг топологии, используя централизованный стек управления программным обеспечением и создание собственного программного обеспечения и оборудования с использованием пользовательских протоколов, адаптированных к центру обработки данных.
10. Почему сети обработки данных Google считаются общей инфраструктурой?
Google Datacenter Networks Power как внутренняя инфраструктура, так и услуги, а также платформу Google Cloud. Это означает, что те же сети доступны для разработчиков по всему миру, что позволяет им использовать сетевую инфраструктуру мирового класса без необходимости ее самостоятельно.
11. Как Google обеспечивает доступность их сети обработки данных обработки данных?
Операционная команда Google развернула и повторно развернула несколько поколений своей сети через свою инфраструктуру, чтобы удовлетворить потребности в распределенных системах полосы пропускания. Они тесно сотрудничают с лучшей в мире сетевой инженерной и операционной командой, чтобы обеспечить доступность их сетей.
12. Какова цель Andromeda на платформе Google Cloud?
Андромеда служит точкой оркестровки для обеспечения, настройки и управления виртуальными сетями и обработкой пакетов в сети на платформе Google Cloud Platform. Это ключевой компонент сетевых возможностей платформы.
13. Как сетевая инфраструктура DataCenter в Google использует программное обеспечение, определяющее сеть (SDN)?
Google развертывает SDN в своей сетевой инфраструктуре обработки центров обработки данных. Они использовали SDN для питания своего WAN, B4, а также стека виртуализации сети, Andromeda. Они приняли архитектурные идеи SDN в своих сетевых системах.
14. Каково значение инвестиций Google в центры обработки данных и офисов?
Инвестиции Google в размере 9 долларов.5 миллиардов в центрах обработки данных и офисов отражают их приверженность расширению их инфраструктуры и возможностей. Это демонстрирует их уверенность в росте их услуг и растущий спрос на Google Cloud.
15. Как сетевая инфраструктура DataCenter в Google способствует платформе Google Cloud Platform?
Сетевая инфраструктура обработки данных Google – это общая инфраструктура, которая поддерживает как внутреннюю инфраструктуру, так и услуги Google, так и услуги Google Cloud Platform. Это позволяет разработчикам по всему миру использовать сетевую инфраструктуру мирового класса без необходимости ее создавать сами, позволяя им создавать инновационные интернет-услуги и платформы.
Google представляет новый центр обработки данных в размере 750 млн. Долл. США как часть $ 9.5B Цель
Машинное обучение является неотъемлемой частью больших данных. Как сказал Райан Ден Руайен, глобальные возможности, Insights & Innovation, в Лондоне (март 2017 г.) (март 2017 г.), “Большинство проблем, которые я наблюдал.” Следовательно, в дополнение к использованию машинного обучения для таких продуктов, как Google Translate, Google также использует свои нейронные сети для прогнозирования осадки своих центров обработки данных.
Собственный Google Datacenter
VP & GM, Инфраструктура систем и услуг
Google уже давно является пионером в распределенной вычислительной и обработке данных, от файловой системы Google до MapReduce до BigTable и Borg. С самого начала мы’Знал, что отличная компьютерная инфраструктура, подобная этой. Но когда Google начал, никто не сделал сеть обработки данных, которая могла бы удовлетворить наши распределенные вычислительные требования.
Итак, в течение последнего десятилетия мы создаем собственное сетевое оборудование и программное обеспечение для подключения всех серверов в наших обработках обработки данных, питание наших систем распределенных вычислений и хранения. Теперь мы открыли эту мощную и преобразующую инфраструктуру для использования внешними разработчиками через Google Cloud Platform.
На саммите Open Network 2015 мы впервые показали детали пяти поколений нашей собственной сетевой технологии. От Firehose, нашей первой внутренней сети обработки данных, десять лет назад до нашей сети Jupiter последнего поколения, мы’VE увеличил емкость одной сети обработки данных более 100 раз. Наше нынешнее поколение – ткани Юпитера – могут обеспечить более 1 петабит/с общей пропускной способности поперечного раздела. Чтобы поместить это в перспективу, такой способности будет достаточно, чтобы 100 000 серверов обменивались информацией по 10 ГБ/с каждая, достаточно для прочтения всего отсканированного содержимого библиотеки Конгресса менее чем за 1/10 секунды.

Мы использовали три ключевых принципа при разработке наших сетей обработки данных:
- Мы организуем нашу сеть вокруг топологии Clos, конфигурации сети, где расположена коллекция меньших (более дешевых) коммутаторов для обеспечения свойств гораздо большего логического переключателя.
- Мы используем централизованный стек управления программным обеспечением для управления тысячами коммутаторов в центре обработки данных, что делает их эффективно действовать как одна крупная ткань.
- Мы строим наше собственное программное и аппаратное обеспечение, используя кремний от поставщиков, меньше полагаясь на стандартные интернет -протоколы и больше на пользовательские протоколы, адаптированные к центру обработки данных.
Взятые вместе, наш стек управления сетью имеет больше общего с Google’S Распределенные вычислительные архитектуры, чем традиционные интернет-протоколы, ориентированные на маршрутизатор. Некоторые могут даже сказать, что мы’В развертывании и наслаждении преимуществами программного обеспечения, определенного сети (SDN) в Google на десятилетие. Несколько лет назад мы показали, как SDN питает Google’S Datacenter Wan, B4, один из мира’Самые большие ванны. В прошлом году мы показали детали GCP’S SDN сетевой стек виртуализации, Andromeda. Фактически, архитектурные идеи для обеих этих систем поступают из нашей ранней работы в сети обработки данных о центре обработки данных.
Создание отличных сетей центров обработки данных – это не только создание отличного аппаратного и программного обеспечения. Это’о партнерстве с миром’Лучшая команда сетевой инженерии и операций с первого дня. Наш подход к сети в корне изменяет организацию сети’S Данные, контроль и самолеты управления. Такой фундаментальный сдвиг не происходит без каких -либо ударов, но наша операционная команда больше, чем столкнулась с вызовом. Мы’В развернутых и перераспределенных нескольких поколениях нашей сети по всей нашей инфраструктуре планетарного масштаба, чтобы не отставать от потребностей полосы пропускания наших распределенных систем.
Собрав все это вместе, наши сети обработки данных обеспечивают беспрецедентную скорость в масштабе всего зданий. . Им управляется для доступности, отвечающих требованиям времени выполнения некоторых из самых требовательных интернет -услуг и клиентов. Самое главное, что наши сети обработки данных являются общей инфраструктурой. Это означает, что те же сети, которые питают весь Google’S Внутренняя инфраструктура и услуги также питают Google Cloud Platform. Мы больше всего рады открыть эту возможность для разработчиков по всему миру, чтобы следующая великая интернет-сервис или платформа могла использовать сетевую инфраструктуру мирового класса без необходимости ее изобретать.
Google Cloud
Введите зону Andromeda: новейший сетевой стек Google Cloud Platform
Andromeda-это программное обеспечение, определенное сетью (SDN) субстрат для наших усилий по виртуализации сети. Это точка оркестровки для обеспечения, настройки и управления виртуальными сетями и обработкой пакетов в сети.
Амин Вахдат • 3-минутное чтение

- Google Cloud
- Инфраструктура
- Система
Google представляет новый центр обработки данных в размере 750 млн. Долл. США как часть $ 9.5B Цель
Поскольку спрос на Google Cloud Soars, Google создает новый центр обработки данных в Небраске в рамках своей стратегии инвестирования 9 долларов США.5 миллиардов в центрах обработки данных и офисов в 2022 году.

Google выполняет свое обещание потратить 9 долларов.5 миллиардов на новых центрах и офисах Google в 2022 году с открытием нового центра обработки данных в 750 миллионов долларов США в Небраске.
Массивный новый кампус Google в Омахе, NEB., будет состоять из четырех зданий на общую сумму более 1.4 миллиона квадратных футов, поскольку спрос на облачные сервисы Google и инфраструктура растут. В Google Cloud’S недавний четвертый квартал, компания сообщила о росте продаж на 45 процентов в год до 5 долларов.5 миллиардов.
“[Новый центр обработки данных] принесет больше возможностей местному сообществу и большему количеству ресурсов для наших клиентов для развития своего бизнеса и использования цифровых услуг,” сказала Стейси Траки Мигер, управляющий директор Google Cloud’Центральный регион в заявлении.
Новый центр обработки данных Google в Небраске является частью Маунтин -Вью, Калифорния.-Основанный поиск и облачный гигант’S планирует инвестировать в общую сумму 9 долларов.5 миллиардов в центрах обработки данных и U.С.-Основанные офисы к концу 2022 года.
Google является одним из крупнейших расходов на создание новых обрабочных центров по всему миру, по данным Synergy Research Group, которая ежегодно инвестирует миллиарды в построение и оснащение центров обработки данных гиперсекции для удовлетворения растущих требований клиентов облака. Google, Amazon Web Services и Microsoft имеют самые широкие следы центра обработки данных в мире, причем каждый хостинг не менее 60 или более местоположений дата -центра.
Центры обработки обработки данных – это “жизненно важные якоря” Клиентам и местным сообществам, сказал генеральный директор Google Sundar Pichai в посте в блоге в этом месяце.
“Наши инвестиции в центры обработки данных будут продолжать питание цифровых инструментов и услуг, которые помогают людям и предприятиям процветать,” сказал Google’S Pichai.
Google’S Планы расширения центра обработки данных
В дополнение к новому дата -центру в штате Небраска, Google планирует потратить миллиарды в этом году на центры обработки данных в Грузии, Айове, Оклахоме, Неваде, Теннесси, Вирджинии и Техасе.
“В U.С. За последние пять лет мы’В инвестировал более 37 миллиардов долларов в наши офисы и центры обработки данных в 26 штатах, создав более 40 000 рабочих мест на полный рабочий день. Что’S в дополнение к исследованиям и разработкам более 40 миллиардов долларов, которые мы инвестировали в U.С. в 2020 и 2021 годах,” сказал Пичай.
Центры обработки обработки данных обеспечивают Google Cloud Services и Infrastructure, включая предложение Flagship Google Cloud Platform (GCP).
В 2021 году GCP зарегистрировал более чем 80 -процентный рост общего объема сделок по сравнению с 2020 годами и более чем на 65 процентов роста числа сделок, превышающих 1 миллиард долларов США.
В целом, Google Cloud теперь имеет годовой ставку выручки в 22 доллара США.16 миллиардов.
Google Data Center FAQ Часть 3
Как Google решает, где создавать свои центры обработки данных?
Google выбирает местоположение своих центров обработки данных на основе комбинации факторов, которые включают местоположение клиента, доступную рабочую силу, близость к инфраструктуре передачи, налоговые скидки, ставки по коммунальным услугам и другие связанные факторы. Недавнее внимание к расширению облачной инфраструктуры добавило больше соображений, таких как спрос клиентов корпоративного облака для определенных мест и близость к центрам населения высокой плотности.
Выбор Св. Ghislain, Бельгия за центр обработки данных (который открылся в 2010 году), была основана на сочетании энергетической инфраструктуры, развиваемой земли, сильной местной поддержке высокотехнологичных рабочих мест и наличии технологического кластера предприятий, которые активно поддерживают технологическое образование в соседних школах и университетах.
Положительный бизнес -климат – еще один фактор. Это, в сочетании с доступной землей и властью, сделало Оклахому особенно привлекательным, согласно Google’Старший директор по операциям, когда был объявлен сайт Pryor Creek. В Орегоне позитивная бизнес -среда означает местонахождение в штате, в котором нет налога с продаж. Местные комиссары округа WASCO также освободили Google для большей части своих налогов на недвижимость, одновременно требуя от его единовременного выплаты в размере 1 доллара США.7 местным органам власти и платежам по меньшей мере 1 миллион долларов каждый год после.
Близость к источникам возобновляемой энергии тоже становится все более важной. Google стратегически инвестируется в возобновляемые ресурсы и рассматривает его экологическое присутствие при размещении новых центров обработки данных.
Используют ли центры обработки данных Google возобновляемая энергия?
Google покупает больше возобновляемой энергии, чем любая корпорация в мире. 2016 он купил достаточно энергии, чтобы учесть более половины использования энергии. В 2017 году компания рассчитывает полностью компенсировать все свои энергетики со 100 -процентной возобновляемой энергией. Для этого Google подписал 20 соглашений о покупке на 2.6 гигаватт (ГВ) возобновляемых источников энергии. Это означает, что, хотя возобновляемая энергия может быть недоступна повсюду или в количестве потребностей Google, Google приобретает такое же количество возобновляемых источников энергии, что и она потребляет.
Google также забрал 2 доллара.5 миллиардов акционерных средств для разработки солнечной и ветровой энергии, которое можно добавить в энергетическую сетку по всему миру. Эта готовность к финансированию возобновляемых проектов является попыткой постепенно расширить рынок возобновляемых источников энергии с точки зрения доступных, а также путем изменения способов приобретения возобновляемых источников энергии можно. В процессе использование возобновляемых источников становится проще и более экономически эффективным для всех.

Просмотр центра обработки данных Google в Хамине, Финляндия, с ветряной турбиной рядом с ним
Устойчивость и в центре обращения в центре обработки данных. Ул. Гислан, Бельгия, центры обработки данных были Google’Сначала полагаться полностью на бесплатное охлаждение. И этот объект’S на сайте завода для очистки воды позволяет центрам обработки данных перерабатывать воду из промышленного канала, а не постучать по региону’S Fress Water Supply.
Сколько энергии используют центры обработки данных Google?
Использование энергии центра обработки данных представляет собой значительный кусок 5.7 часов часов, ее материнская компания, Alphabet, используется в 2015 году. Со средним шрифтом 1.12 (в среднем по отрасли 1.7), Google говорит, что в его центрах обработки данных используется половина энергии типичного центра обработки данных. Растущая часть этого является возобновляемой, поставляется через соглашения о покупке электроэнергии.
Какое оборудование и программное обеспечение использует Google в своих центрах обработки данных?
Это’Не секрет, что Google создал свою собственную интернет-инфраструктуру с 2004 года из товарных компонентов, что привело к ловким программным центрам обработки данных. Полученная иерархическая конструкция сетки является стандартной во всех его центрах обработки данных.
В оборудовании доминируют пользовательские серверы и Юпитер, разработанные Google, Google, введенный в 2012 году. Благодаря экономии масштаба Google заключает напрямую с производством, чтобы получить лучшие предложения.

Евгения Свердлик
Google’S Jupiter Networking Switcheres на дисплее в Google Cloud в следующем 2017 году в Сан -Франциско
Google’S серверы и сетевое программное обеспечение запускают закаленную версию операционной системы Linux с открытым исходным кодом. Индивидуальные программы были написаны на месте. Они включают, насколько нам известно:
- Google Web Server (GWS)-пользовательский веб-сервер на основе Linux, который Google использует для своих онлайн-сервисов.
- Системы хранения:
- Colossus-файловая система уровня кластера, которая заменила файловую систему Google
- Кофеин – система непрерывной индексации, запущенная в 2010 году для замены Teragogle
- Hummingbird – Алгоритм основного индекса поиска, представленный в 2013 году.
Google также разработал несколько абстракций, которые он использует для хранения большей части своих данных:
- Буферы протокола-нейтральный язык, нейтральный, нейтральный платформ, расширяемый способ сериализации структурированных данных для использования в протоколах связи, хранении данных и многого другого
- Sstable (таблица отсортированных строк) – постоянная, упорядоченная, неизменная карта от ключей до значений, где как ключи, так и значения являются произвольными байтовыми строками. Он также используется в качестве одного из строительных блоков BigTable
- Recordio – файл, определяющий интерфейсы ввода -вывода, совместимый с Google’S IO спецификации
Как Google использует машинное обучение в своих центрах обработки данных?
Машинное обучение является неотъемлемой частью больших данных. Как сказал Райан Ден Руайен, глобальные возможности, Insights & Innovation, в Лондоне (март 2017 г.) (март 2017 г.), “Большинство проблем, которые я наблюдал.” Следовательно, в дополнение к использованию машинного обучения для таких продуктов, как Google Translate, Google также использует свои нейронные сети для прогнозирования осадки своих центров обработки данных.
Google вычисляет пую каждые 30 секунд и непрерывно отслеживает его нагрузку, температуру внешнего воздуха и уровни механического и охлаждающего оборудования. Эти данные позволяют инженерам Google разработать прогнозирующую модель, которая анализирует сложные взаимодействия многих переменных, чтобы раскрыть паттерны, которые можно использовать для улучшения управления энергией. Например, когда Google взял несколько серверов в автономном режиме в течение нескольких дней, инженеры использовали эту модель для корректировки охлаждения, чтобы поддерживать энергоэффективность и сэкономить деньги. Модель 99.6 процентов точнее.
В июле 2016 года Google объявил о результатах теста системы ИИ благодаря своей британской приобретении DeepMind. Эта система снизила энергопотребление своих охлаждающих единиц центра обработки данных на 40%, а общий уютный. Система предсказывает температуру за час, позволяя корректировать охлаждение в ожидании.
Спаривает ли место Google в других компаниях’ Центры обработки данных?
Да. Google арендует пространство от других, когда это имеет смысл. Не каждый центр обработки данных Google имеет свое название на двери. Вместо этого компания использует различные стратегии для удовлетворения потребностей центра обработки данных. Например, он сдает в аренду место для кэширования сайтов и использует смешанную стратегию сборки и аренды для своего глобального развертывания облачных центров данных.
Собственный Google Datacenter
Амин Вахдат
VP & GM, Инфраструктура систем и услуг
Сети центров обработки данных составляют основу для современного масштаба склада и облачных вычислений. Основная гарантия единой, произвольной связи между десятками тысяч серверов на 100-х годах Гбит/с полосы пропускания с задержкой суб-100US преобразовал вычисления и хранилище. Основное преимущество этой модели является простым, но глубоким: добавление инкрементного сервера или устройства для хранения в службу более высокого уровня обеспечивает пропорциональное увеличение обслуживания и возможностей. В Google наша технология сети данных Jupiter Data Center поддерживает такого рода возможности масштабирования для основополагающих услуг для наших пользователей, таких как поиск, YouTube, Gmail и облачные сервисы, такие как AI и машинное обучение, вычислительный двигатель, аналитика BigQuery, базы данных Spanner и десятки.
Мы провели последние восемь лет, глубоко интегрируя оптическое переключение (OCS) и мультиплексирование дивизии волны (WDM) в Юпитер. В то время как десятилетия традиционной мудрости предположило, что это нецелесообразно, комбинация OCS с нашей архитектурой сети, определенной нашим программным обеспечением (SDN), позволила новые возможности: поддержка инкрементных сетевых сборки с гетерогенными технологиями; более высокая производительность и более низкая задержка, стоимость и энергопотребление; Приоритет приложения в реальном времени и модели связи; и обновления нулевого времени. Юпитер делает все это при сокращении завершения потока на 10%, повышая пропускную способность на 30%, используя на 40% меньше мощности, что составляет на 30% меньше затрат, и обеспечивая 50 раз меньше времени простоя, чем самые известные альтернативы. Вы можете прочитать больше о том, как мы сделали это в статье, которую мы представили в SigComm 2022 сегодня, Jupiter Evolving: преобразование сети DataCenter Google через оптические схемы и программные сети, определенные сетью.
Вот обзор этого проекта.
Развивающиеся сети центров обработки данных Юпитера
В 2015 году мы показали, как наши сети центров обработки данных Jupiter масштабировались до более чем 30 000 серверов с единой подключением 40 ГБ/с на сервер, что поддерживает более 1pb/Sec агрегатной полосы пропускания. Сегодня Jupiter поддерживает более 6 пб/с/с полосы пропускания обработки данных DataCenter. Мы доставили этот никогда ранее невидимый уровень производительности и масштаба, используя три идеи:
- Программное обеспечение определяет сеть (SDN) – Логически централизованная и иерархическая плоскость управления для программирования и управления тысячами переключающих чипов в сети центра обработки данных.
- Кличная топология – Неблокирующая многоступенчатая топология переключения, созданную из более мелких чипов Radix Switch, которая может масштабироваться до произвольно больших сетей.
- Торговый переключатель кремний – Экономически эффективные компоненты компонента коммутации Ethernet Ethernet общего назначения для конвергентного хранилища и сети данных.
Строившись на этих трех столпах, Юпитер’А архитектурный подход поддержал морское изменение в архитектуре распределенных систем и установил путь для того, как отрасль в целом строит и управляет сети центрами обработки данных.
Тем не менее, две основные проблемы для центров обработки данных остались. Во -первых, сети центров обработки данных необходимо развернуть в масштабе всего здания – возможно, 40 МВт или более инфраструктуры. Кроме того, серверы и устройства для хранения, развернутые в здании, всегда развиваются, например, с 40 ГБ/с до 100 ГБ/с до 200 Гбит/с и сегодня 400 ГБ/с. Следовательно, сеть центров обработки данных необходимо динамически развиваться, чтобы идти в ногу с новыми элементами, подключающимися к ней.
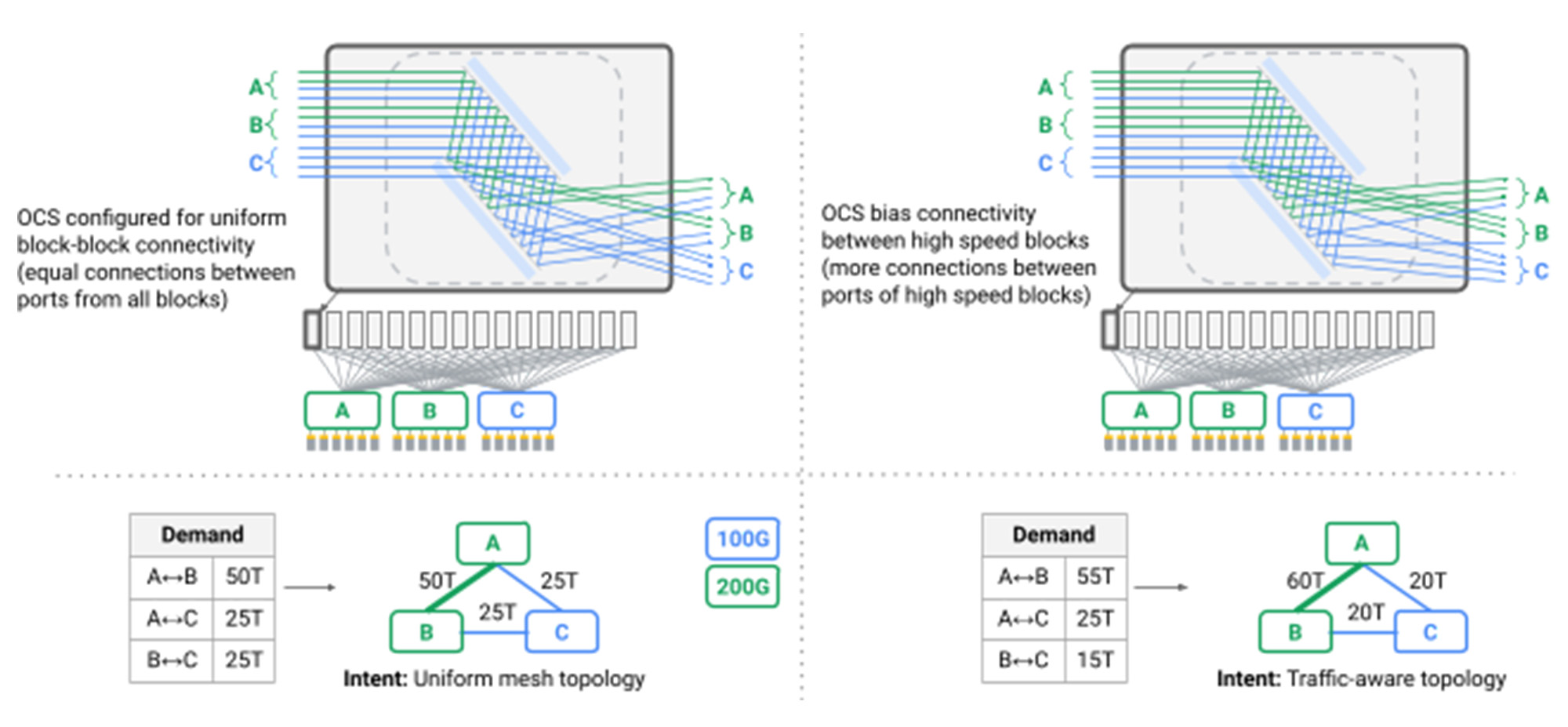
К сожалению, как показано ниже, топологии для закрытия требуют слоя позвоночника с равномерной поддержкой самых быстрых устройств, которые могут подключиться к нему. Развертывание сети на основе центров обработки данных в здании означало предварительное развертывание очень большого уровня позвоночника, который работал с фиксированной скоростью последнего поколения дня. Это связано с тем, что топологии по своей природе требуют Все-все фанат от блоков агрегации 1 до позвоночника; Добавление к позвоночнику постепенно потребует повторного проваления всего центра обработки данных. Одним из способов поддержки новых устройств, работающих по более быстрым показателям линии, было бы заменить весь слой позвоночника, чтобы поддержать более новую скорость, но это было бы нецелесообразно, учитывая сотни отдельных стойков, размещающих переключатели и десятки тысяч волоконных пар, проходящих через здание.
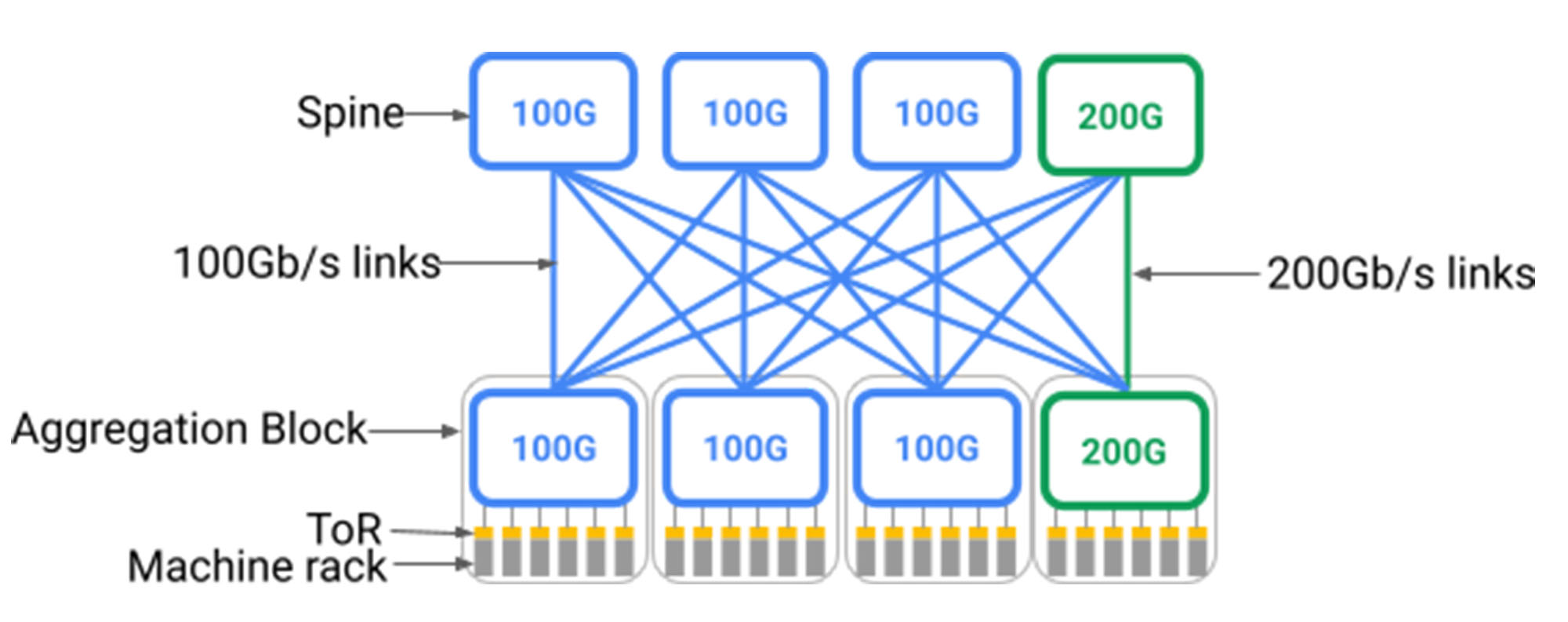
инжир. Новый блок агрегации (зеленый) со скоростью порта 200 Гбит/с подключен к 3 старым блокам позвоночника (синий) со скоростью порта 100 ГБ/с и одним новым блоком позвоночника (зеленый) со скоростью порта 200 ГБ/с. В этой модели только 25% ссылок из нового блока агрегации и нового блока позвоночника работают на 200 ГБ/с.
В идеале, сеть центров обработки данных будет поддерживать гетерогенные элементы сети в “платить по мере роста” модели, добавление сетевых элементов только при необходимости, и постепенно поддерживая технологии последнего поколения. Сеть будет поддерживать ту же идеализированную модель масштабирования, которую она обеспечивает серверы и хранение, что позволяет постепенно добавлять емкости сети-даже если из-за другой технологии, чем ранее развернутая-для обеспечения увеличения пропорциональной емкости и собственной взаимодействия для всего строительства устройств.
Во-вторых, в то время как равномерная пропускная способность в масштабе зданий является силой, она становится ограничивающей, если учесть, что сети обработки центров обработки данных по своей природе являются мультитенантными и непрерывно подчиняющимися к обслуживанию и локализованным сбоям. Единственная сеть центров обработки данных проводит сотни отдельных услуг с различными уровнями приоритета и чувствительности к пропускной способности и вариации задержки. Например, обслуживание результатов поиска веб-сайта в режиме реального времени может потребовать гарантий задержки в режиме реального времени и распределения полосы пропускания, в то время как многочасовая пакетная аналитическая задача может иметь больше гибких требований к полосе пропускания в течение коротких периодов времени. Учитывая это, сеть центров обработки данных должна распределять пропускную способность и путь для услуг на основе моделей связи в реальном времени и оптимизации с учетом приложений сети. В идеале, если 10% мощности сети должны быть временно сняты для обновления, то 10% не должны быть равномерно распределены по всем арендаторам, но распределяются на основе индивидуальных требований и приоритета приложения.
Решение этих оставшихся проблем сначала казалось невозможным. Сети центров обработки данных были построены вокруг иерархических топологий в массовом физическом масштабе, так что поддержка инкрементной гетерогенности и динамической адаптации применения не может быть включена в дизайн. Мы сломали этот тупик, разработав и представляя Оптическая схема переключения (OCS) в архитектуру Юпитера. Оптический переключатель схемы (изображено ниже) отображает оптический волоконно-входной порт в выходной порт динамически через два набора зеркал микроэлектромеханических систем (MEMS), которые можно вращать в двух измерениях для создания произвольных сопоставлений порта в порт.
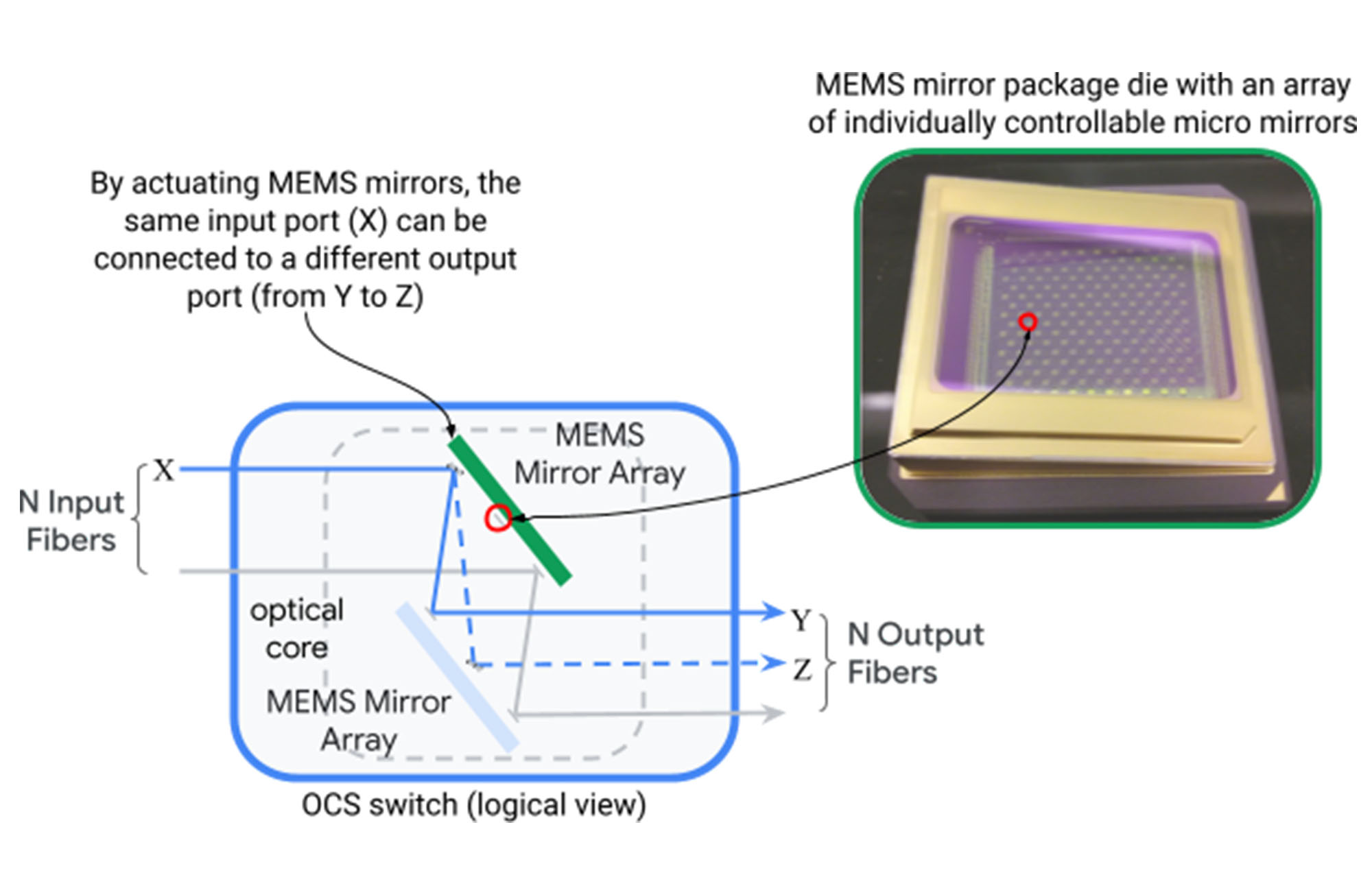
инжир. Работа одного отображения устройства OCS N входов в n выходных волокон через зеркала MEMS.
У нас было представление о том, что мы могли бы создать произвольные логические топологии для сетей центров обработки данных, введя уровень посредничества OCS между переключателями пакетов центра обработки данных, как показано ниже.
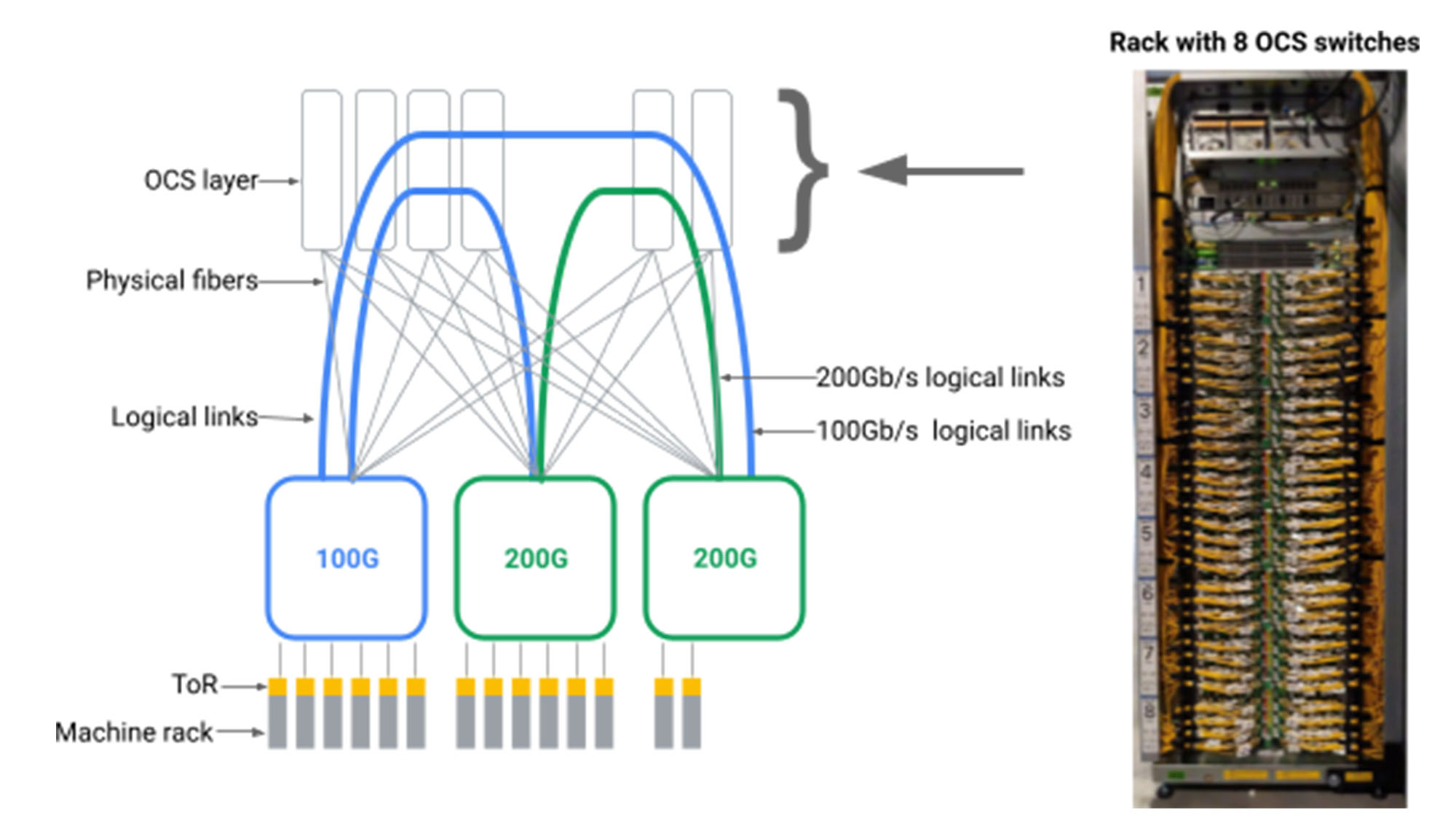
инжир. Блоки агрегации физически подключены через волокна к переключателям OCS. Логическая топология может быть реализована путем настройки каждого переключателя OCS для подключения перестановки ввода к выходным волокнам.
Это потребовало от нас создания OCS и местных приемопередатчиков WDM с уровнями масштаба, производительности, программируемости и надежности, которые никогда не достигнуты ранее. В то время как академические исследования исследовали преимущества оптических переключателей, традиционная мудрость предположила, что технология OCS не была коммерчески жизнеспособной. В течение нескольких лет мы разработали и построили Аполлон OCS Это теперь составляет основу для подавляющего большинства наших сетей центров обработки данных.
Одна важная выгода OCS заключается в том, что в ее эксплуатации не участвует никакая маршрутизация пакетов или анализа заголовков. OCS просто отражает свет от входного порта до выходного порта с невероятной точностью и небольшими потерями. Свет генерируется путем электрооптического преобразования при приемопередатчиках WDM, уже необходимых для надежно и эффективного передачи данных в зданиях центров обработки данных. Следовательно, OCS становится частью Строительство инфраструктуры, Является ли скорость обработки данных и длины волны и не требует обновлений, даже несмотря на то, что электрическая инфраструктура перемещается от скорости передачи и кодирования от 40 ГБ/с до 100 ГБ/с до 200 ГБ/с – и выше.
С помощью уровня OCS мы устранили уровень позвоночника из наших сетей центров обработки данных, вместо этого соединив гетерогенные блоки агрегации в прямой сетке, впервые выходя за пределы топологий в обращении в центре обработки данных. Мы создали динамические логические топологии, которые отражали как физические способности, так и модели связи приложений. Пересмотр логического подключения, наблюдаемой коммутаторами в нашей сети, теперь является стандартной рабочей процедурой, динамически развивающая топологию от одного шаблона к другой, без какого-либо визитного воздействия. Мы сделали это, координируя стоки ссылки с помощью программного обеспечения для маршрутизации и реконфигурации OCS, полагаясь на нашу плоскость управления сетью, определяющую программное обеспечение Orion, чтобы бесшовно организовать тысячи зависимых и независимых операций.
инжир. Многочисленные OC, достигающие топологии
Особенно интересная задача заключалась в том, что впервые кратчайшие маршрутизацию пути по топологии сетки больше не могли обеспечить производительность и надежность, требуемая в нашем центре обработки данных. Побочным эффектом обычно развернутых топологий Clos является то, что, хотя многие пути доступны через сеть, все они имеют одинаковую длину и емкость, так что, не обращая внимания на распределение пакетов, или Вариант балансировка нагрузки, обеспечивает достаточную производительность. В Юпитере мы используем нашу плоскость управления SDN, чтобы ввести динамику Тророристическая инженерия, Принятие методов, первых для Google’S B4 WAN: мы разделили трафик между несколькими самыми короткими и неплощенными путями, наблюдая за пропускной способностью, шаблонами связи в реальном времени и индивидуальном приоритете применения (красные стрелки на рисунке ниже).
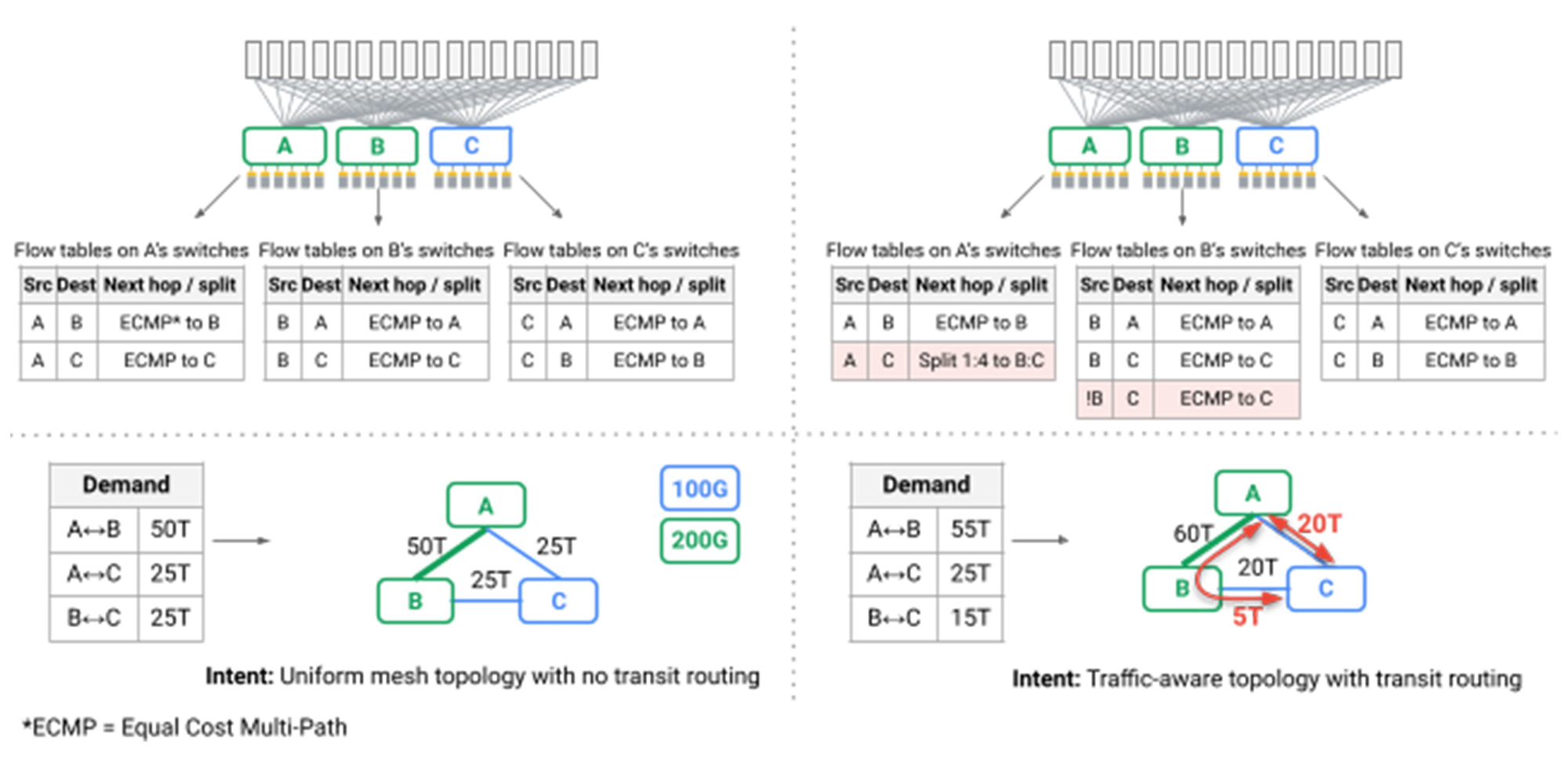
инжир. Поточные таблицы на переключателях выполняют инженерию для дорожного движения
Взятые вместе, у нас итеративно полностью пересмотрели сети центров обработки данных Юпитера, которые питают Google’S-складские компьютеры, представляющие ряд отраслевых первых на этом пути:
- Оптические схемы переключаются в качестве точки совместимости для сетей в масштабе здания, беспрепятственно поддерживая гетерогенные технологии, обновления и требования к обслуживанию.
- Прямые топологии сети на основе сетки для более высокой производительности, более низкой задержки, более низких затрат и более низкого энергопотребления.
- Топология в режиме реального времени и инженерия трафика для одновременного адаптации сетевого подключения и пути для соответствия приоритетным приложениям и моделям связи, при этом наблюдая за обслуживанием и сбоями в реальном времени.
- Обновления сети без удара с локализованным добавлением/удалением емкости, устраняя необходимость в дорогостоящем и трудном “все услуги” Обновления в стиле, которые ранее требовали сотни отдельных клиентов и услуг для перемещения своих услуг для расширенного времени простоя строительства.
Несмотря на то, что базовая технология впечатляет, конечной целью нашей работы является продолжение обеспечения эффективности, эффективности и надежности, которые вместе предоставляют преобразующие возможности для наиболее требовательных распределенных услуг, питание Google и Google Cloud. Как упомянуто выше, наша сеть Юпитера потребляет на 40% меньше энергии, получает на 30% меньше затрат и обеспечивает на 50 раз меньше времени простоя, чем лучшие альтернативы, о которых мы знаем, при этом снижение завершения потока на 10% и повышение пропускной способности на 30%. Мы с гордостью поделились подробностями об этом технологическом подвиге в SigComm сегодня и с нетерпением ждем возможности обсудить наши выводы с сообществом.
Поздравляем и спасибо бесчисленным гуглерам, которые работают на Юпитере каждый день и авторам этого последнего исследования: Леон Поутиевский, Омид Машайеки, Джун Онг, Арджун Сингх, Мукаррам Тарик, Руи Ванг, Цзянь Чжан, Вирджиния Борегард, Патрик Коннер, Стев Грибл, Стев, Стев, Стев, Стев, Стев, Стев, Стеве Грибл, Стеве, Стеве Грибл, Стеве, Стеве Грибл, Стеве, Стеве Грибл. Картик Нагарадж, Джейсон Орнштейн, Самир Соухни, Рёхей Урата, Лоренцо Вицисано, Кевин Ясумура, Шидонг Чжан, Джунлан Чжоу, Амин Вахдат.
1. Блок агрегации содержит набор машин (вычислительный/хранение/ускоритель), включая переключатели с верхним входом (TOR), подключенные слоем обычно совместных переключателей.